Nous avons observé une dégradation importante des temps de réponses lors de l’affichage de listes depuis le déploiement de la P24 (en mars/avril dernier) qui est devenue beaucoup plus prononcée (avec impact métier important) depuis que nous sommes contraints de travailler à distance par VPN (en environnement Intranet / réseau interne, la dégradation est moins sensible).
En creusant le sujet, j’ai pu déterminer que chaque row de liste embarque l’ensemble des métadonnées de chaque champ de l’objet listé. L’effet est désastreux sur un objet en particulier qui embarque 240 champs (je tend le bâton pour le faire battre, je sais; il s’agit d’un objet modélisé pour nos juristes et il est comme les codes et réglementation avec lesquels ils travaillent…on ajoute mais on enlève jamais ou rarement).
Je précise que l’affichage en liste a été optimisé (fonctionnellement) en configurant uniquement quelques champs visibles en liste / le reste en formulaire seulement. Hors, les métadonnées servies au front lors du rendu de la liste embarquent aussi les champs configurés en formulaire seulement.
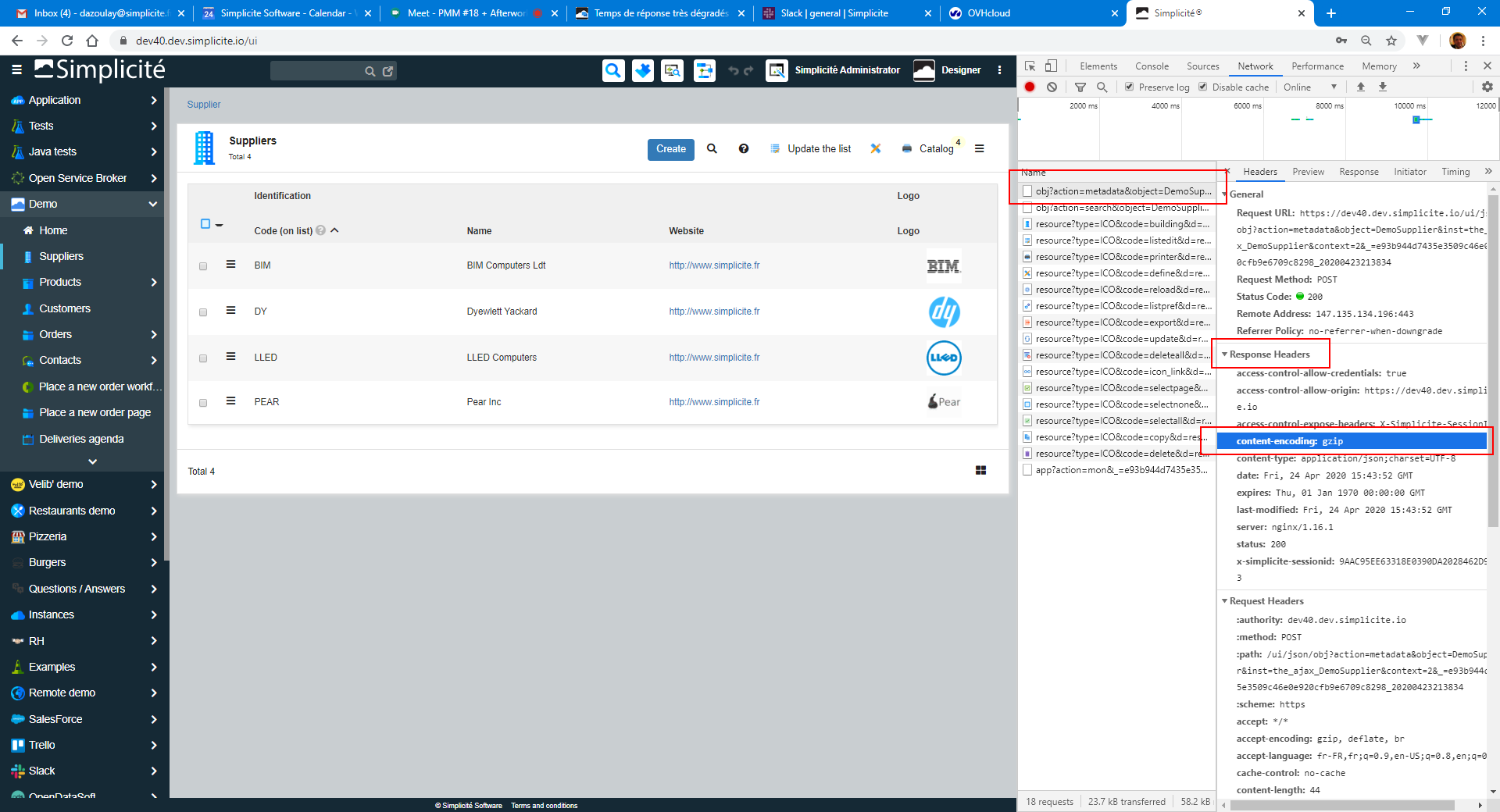
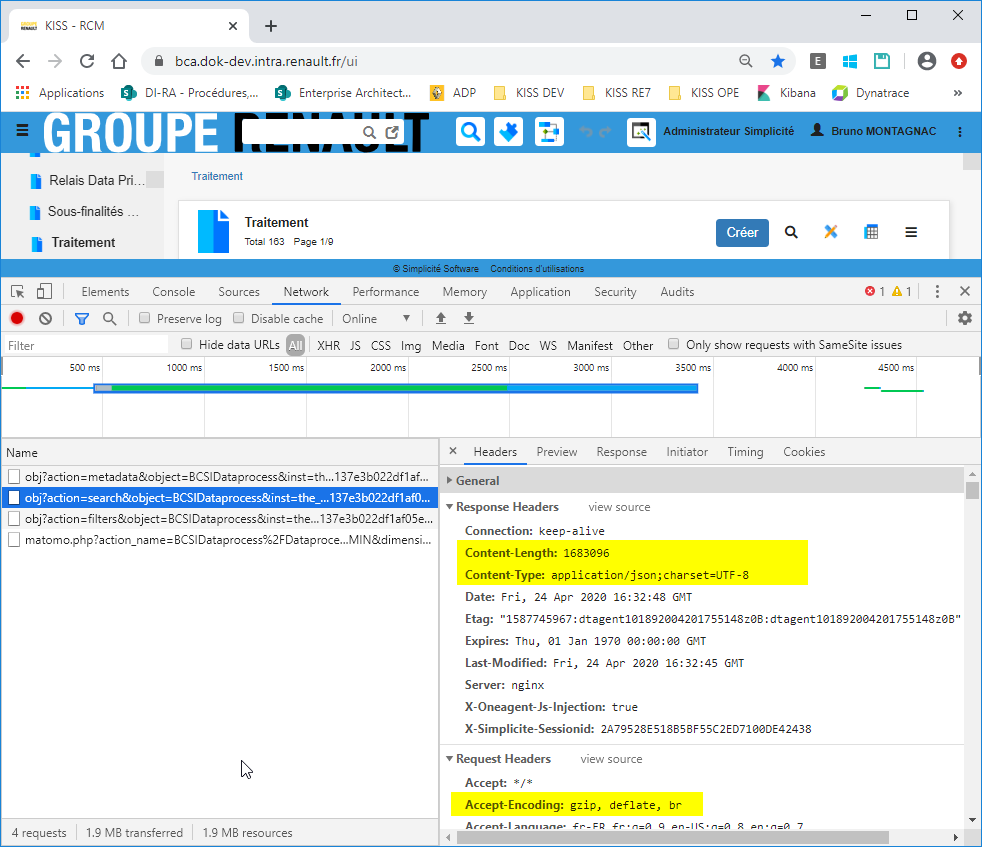
De ce fait, la volumétrie du json servi est énorme (~100ko en moyenne par record(metadata+data) pour un total de 2Mo par page de 20 items).
Est-il envisageable de filtrer les métadonnées aux champs visibles dans la liste ou (compte tenu du fait que la plupart des métadonnées sont les mêmes pour chaque ligne) de factoriser l’arbre des métadonnées?
C’est normalement le cas, l’optimisation avait été faite il y a longtemps sur les listes.
Les attributs remontés (meta + data) sont uniquement ceux de la liste sauf pour 2 exceptions :
présence de contrainte inter-champs sur l’objet : même invisible, la UI peut en avoir besoin pour calculer qq chose sur ceux visibles
ou bascule en liste éditable : on affiche les attributs modifiables mais il faut aussi les champs cachés
Car là il faut potentiellement tous les champs pour valider les hooks front.
Je vais vérifier qu’il n’y a pas de régression à ce niveau.
Bonsoir François,
merci beaucoup pour ton analyse.
Je pense qu’il y a des marges d’amélioration dans les champs activés en recherche (ils le sont quasiment tous). Par contre, de nombreux champs (form only) sont soumis à des contraintes et là ça risque de coincer. Je vais faire le ménage au maximum.
C’est vrai qu’avant on ne remontait pas les champs en recherche, c’est devenu nécessaire pour permettre d’afficher les filtres (sous forme de badge) sur des champs qui ne sont justement pas en liste. On doit pouvoir optimiser ça sur les champs dont les filtres sont non vides uniquement, les autres ne servent à rien sur la liste (à vérifier tout de même).
Pour les contraintes, ça doit pouvoir s’optimiser de notre côté si on peut mieux cerner le contexte (contrainte back uniquement, ou formulaire = context update). Comment sont paramétrées vos contraintes ?
Bonjour François,
sur l’objet concerné, la plupart des contraintes sont front (pour que l’utilisateur puisse voir l’effet sans attendre un enregistrement) :
12 contraintes de visibilité de zones d’attributs (54 champs concernés)
78 contraintes de réinitialisation de valeur, visibilité ou obligatoire (44 champs concernés)
Bruno
Ok je vais regarder les pistes d’amélioration pour limiter les méta-data remontées sur chaque ligne.
Pour les contraintes front, il va falloir trouver un moyen de savoir si elles s’appliquent à la liste ou pas.
Ont elles une condition de type [CONTEXT:UPDATE] pour limiter les impacts au seul formulaire ?
Car si la condition est “true” elles s’appliquent partout et il ne sera pas possible de filtrer sans aller chercher les types d’impact (visibilité du champ ou valeur forcée).
D’un point de vue conceptuel, un tel objet typé à champs “à tiroir” peut-il se rapprocher d’une modélisation par héritage limitant les attributs de chaque héritier “typé” sans avoir besoin de passer par des contraintes sur un gros objet chapeau ? L’objet chapeau n’aurait alors que les attributs communs en liste + un getTargetObjet pour rediriger vers des héritiers typés avec leurs champs supplémentaires.
Oui le pattern par héritage (autrement appellé le pattter “legume > choux ou carotte”) est peut être la bonne approche.
Une autre approche c’est de mettre les règles de visibilité conditionnelle des attributs dans du code serveur ìnitUpdate/Create/Delete/List` plutôt que sous forme de contraintes.
Sinon sur un autre cas j’avais un objet à plus de 400 attributs que j’ai implémente avec une logique de toggle “fort” en fonction du “theme” actif (par toggle “fort” je veux dire que dans les initXXX je mets tous les attributs en forbidden sauf ceux du thème actif ou de la liste quand j’affiche la liste, à noter qu’en update un changement de theme déclenche un save), avec cette stratégie j’avais au max 20-30 attributs actifs sur le formulaire (et une dizaine en liste/recherche) et du coup des temps de réponse nickel malgré la monstruosité de l’objet (les attributs forbidden sont exclus des metadonnées/données)
Merci beaucoup pour vos retours et recommandations.
J’ai déjà commencé à faire le tri sur les options utiles de recherche (souvent, l’option de recherche est active par défaut dans l’objet détenteur mais la recherche n’est pas forcément requise dans l’objet qui importe ces propriétés via une foreign key).
Je vais en effet aussi regarder du côté du “[CONTEXT:UPDATE]” (toutes mes contraintes sont “true” ou “false” si désactivées globalement à la marge).
La piste du cloisonnement par héritage est intéressante mais certains aspects ne sont pas encore bien couverts (héritage des options d’association par exemple) donc je n’utilise cette possibilité que si je n’ai pas pu faire autrement / en fonction du rapport coût/bénéfice.
Je vais voir dans quelles mesures ces options améliorent la situation.
Après analyse de notre côté, il apparaît qu’on peut bien limiter les meta de chaque ligne car on récupère déjà les champs “visible ou présent en recherche ou en contrainte ou dans un placemap” dans les meta de l’objet lui-même dans le service search. Chaque ligne peut donc ne recevoir que les fields visibles uniquement (les autres seront repris de ceux de l’objet pour pouvoir appliquer les contraintes), mais il faut bien envoyer les data (visibles ou en contrainte de champs cachés) de chaque lignes.
C’est donc une optim sans impact sur votre code ou votre paramétrage (même si mette [CONTEXT:UPDATE] permettrait de limiter le scope d’application, ou retirer des recherches fulltext est une autre forme d’optimisation à la main du designer).
PS : pour désactiver un contrainte, il faut lui mettre un ordre négatif (en général inverser son signe pour pas perdre l’ordre paramétré), car ça l’exclura de l’objet lors du chargement en mémoire. Ca évite de l’interpréter pour ne rien faire en runtime.
C’est noté et pris en compte (ménage dans les options de recherche et les contraintes).
cela m’a permis de retrouver d’anciennes contraintes sans impact suite à la suppression des champs initialement impactés (un oubli).
Pour l’instant, je n’ai réussi à gagner “que” ~15% sur la volumétrie (1,65Mo->1,43Mo pour 20 lignes sur le compte de test utilisé).
Merci beaucoup.
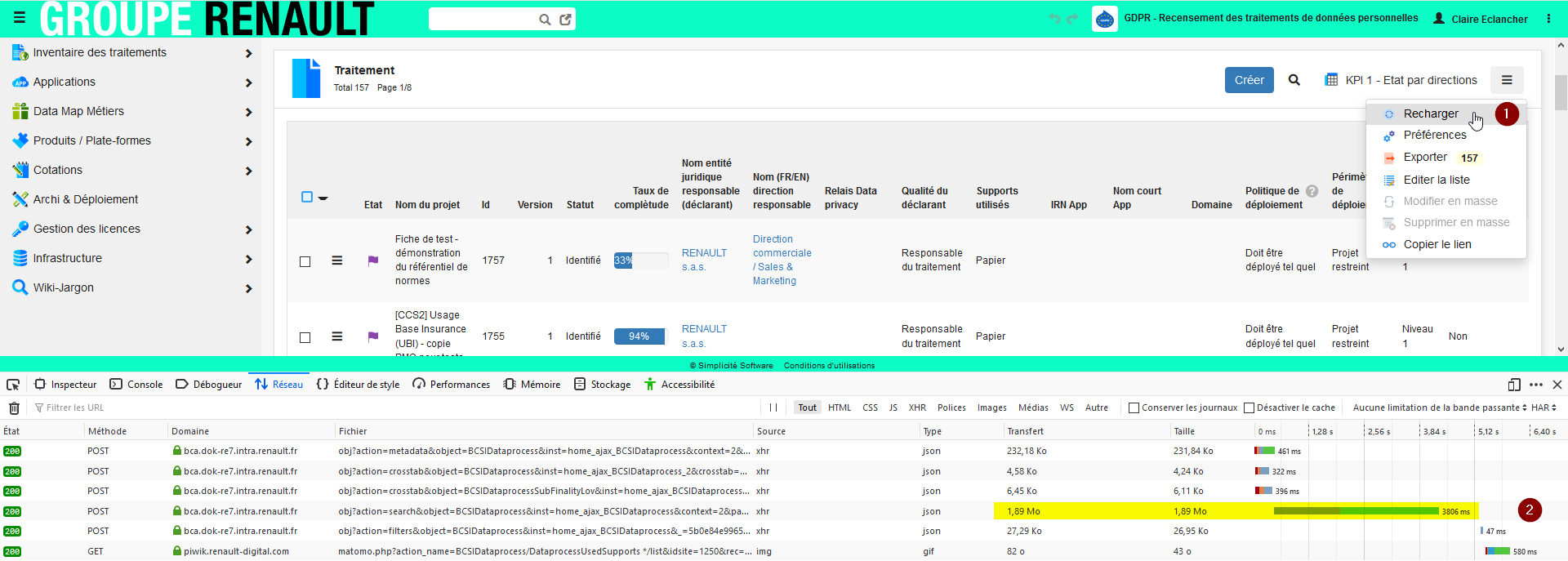
Question bête, est-ce que votre reverse proxy implémente de la compression gzip ?
Sinon ça peut se configurer niveau Tomcat, je ne pense pas que nos images Docker aient un param pour l’activer à la demande car en général ça se fait un niveau du reverse proxy mais ça peut s’envisager
C’est une bonne question…
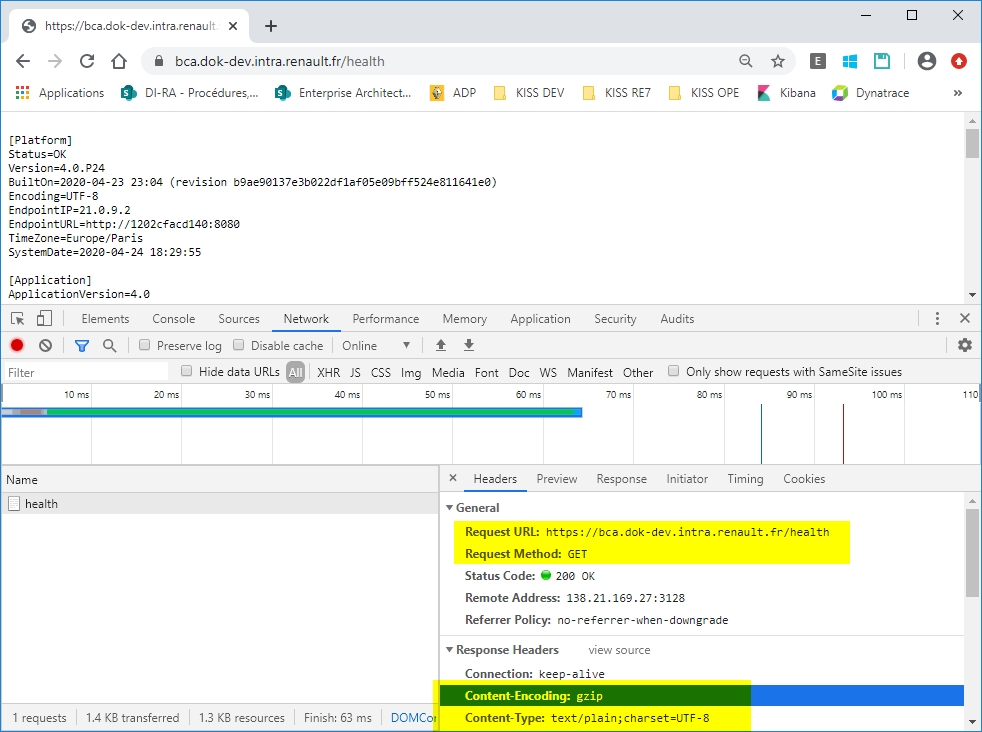
L’entête de la requête contient bien “Accept-Encoding: gzip, deflate, br” mais l’entête de la réponse ne contient apparemment aucun “Content-Encoding: xxx” (ni gzip ni rien d’autre).
Ce qui est curieux, c’est que les headers de la réponse à /health ou /ui/logs contiennent bien “Content-Encoding: gzip” mais pas les headers de la réponse au POST de chargement de la liste…
L’optimisation au niveau des metadata de ligne sera livrée au prochain build. à voir si ça améliore les choses pour votre objet. Normalement, la définition des champs en contrainte ou en recherche n’est plus remontée qu’au niveau de l’objet, et au niveau de chaque ligne :
on n’a que la définition des attributs visibles : car peut avoir été modifiée par le back (hook de postSelect ou contrainte back…)
et les valeurs visibles ou utilisées par des contraintes (mais pas en recherche)
C’est un peu compliqué de traiter chaque cas, mais je ne vois pas d’autres axes d’amélioration généralisables à ce stade.
Nous avons poussé de nouvelles images Docker incluant la possibilité de faire gérer la compression par Tomcat via un -e GZIP=true.
En lançant des containers standalones ça fait ce qu’il faut mais je ne sais pas trop si ça fera bon ménage avec vos diverses couches de reverse proxies… à tester.