Bonjour,
certains utilisateurs utilisent la fonction copier/coller pour saisir dans des champs texte des informations en provenance de supports divers (ex. texte explicatif “GDPR” en pied de page de formulaire de contact sur le site Official Home of Alpine Cars & Racing).
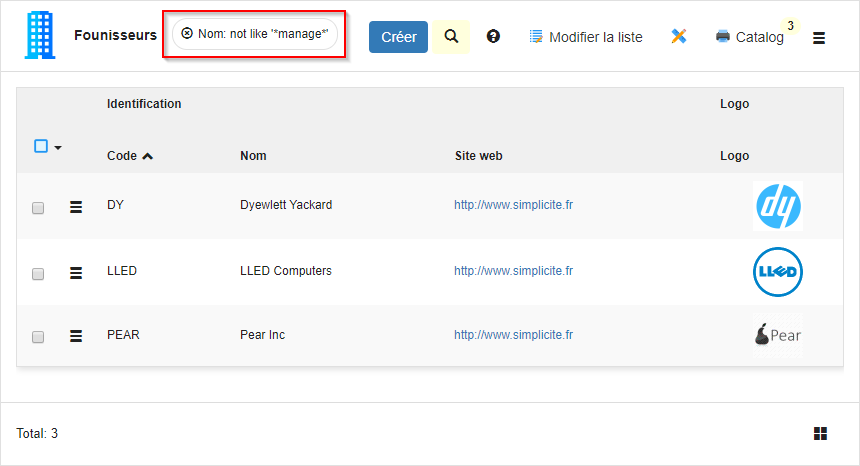
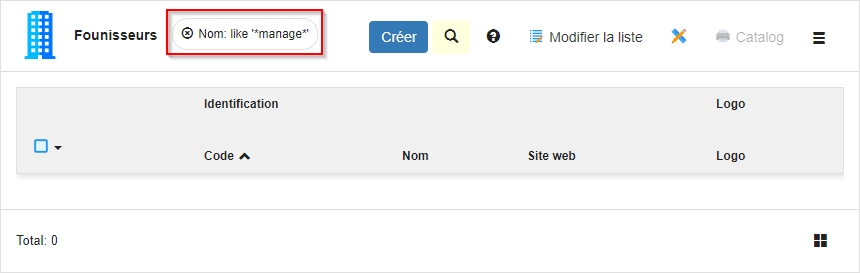
Hors, si le texte copié contient un caractère spécial ou mal encodé (voir la séquence “…requests,manage…” dans le formulaire cité ci-dessus), l’enregistrement est accepté mais une fois la donnée en base, impossible de ré-afficher le formulaire ou la liste intégrant la données fautive.
Pour restaurer le service, il faut manuellement supprimer le caractère dans le champ concerné de la base de données.
→ problème reproduit sur l’instance bcsi.renault.simplicite.io / Démo / Fournisseurs (j’ai simplement collé “requests,manage” / dans le nom d’un fournisseur).
Bruno
Il peut effectivement y avoir des subtilités si on arrive à entrer des caractères hors charset UTF-8.
Je pense qu’il y a des comportements différents en fct du navigateur et de la base de données utilisé. En effet normalement c’est le navigateur qui se sachant dans une page UTF-8 est sensé faire les conversions à la source mais peut être qu’en copiant collant il y a des subtilités.
Bref on va regarder ce qu’on peut faire sur ce point.
Vous pouvez filtrer les caractères autorisés au validate => créer un Type d’attribut avec regexp sur votre attribut textuel.
De quel caractère parle-t-on ? dans quel encoding est-il disponible ?
Je ne vois pas bien ce qu’on peut corriger niveau socle dont l’encoding est un paramètre.
Il faut apprendre à vos utilisateurs à faire click droit / “coller en texte brut” car faire une recherche sur un emoji ou un low-value (0) n’a aucun sens.
Nous allons en effet voir comment filtrer ces données à l’entrée (filtre de validation ou de détection des caractères invalides) et communiquer sur la recommandation / “coller en texte brut” dans la notification qui sera remontée.
L’alerte remontée portait surtout sur le fait que si on ne prévoit pas ce cas en amont, cela plante l’affichage des vues liste et formulaire.
Oui c’est pour cela qu’on doit faire un truc à minima genre retirer les caractères non UTF-8 à l’enregistrement ou remonter une erreur. On va regarder ce qui est faisable
Bonjour David, François,
nous rencontrons ce problème de copier/coller de manière assez dispersée (quoi que ça reste assez rare).
Avez-vous trouvé une solution socle permettant de “nettoyer” le flux avant que ça ne rentre dans la base de données ? ou résoudre le problème d’affichage ?
Merci beaucoup pour votre support et votre expertise.
Les caractères qui historiquement posaient pb en ISO -8859-1[5] (genre les doubles quotes et apostrophes issues de copier/coller depuis MS Office) sont bien dans le charset UTF-8 et ne devraient donc pas poser de pb.
De manière plus générale:
Quand on constitue un fichier XML(pas que pour Simplicité) il faut s’assurer qu’on y met bien des contenus encodés dans le même encoding que celui déclaré dans le header XML. Exemple: si on met <?xml version="1.0" encoding="utf-8"> en header et qu’on y copie/colle des contenus en ISO-8859-1 ou Windows-1252 cela donne un fichier XML incorrect qu’aucun logiciel ne pourra traiter correctement.
Si on parle d’un copier/coller dans un formulaire de la UI, normalement c’est le navigateur qui se charge de faire la conversion car une page web travaille dans l’encoding indiqué, pour les pages Simplicité c’est utf-8
Pour les APIs, celles de Simplicité s’attendent à recevoir de l’utf-8(typiquement dans le contenu JSON envoyé en PUT ou POST) c’est à l’appelant de s’en assurer.
Avez vous cerné précisément quel(s) caractères posent pb et par quel canal ils ont été envoyés ?
Bonjour David, il s’agit bien d’un copier/coller dans un champ de formulaire depuis un client Chrome (pas testé le cas sur d’autres navigateurs).
ça plante l’affichage en liste et en formulaire si le champ est visible.
comme les champs description ne sont souvent pas visibles en liste, c’est surtout l’édition en formulaire qui pose problème.
Le problème se pose (logiquement) aussi dans l’affichage du l’historique.
Par contre, le journal des modifications n’est pas impacté.
Ce qui me permet d’ajouter une belle photo du caractère délinquant:
Et concernant le canal: comme souvent, la cause racine est dans l’interface chaise/clavier et c’est toujours le même utilisateur qui plante ses formulaires…
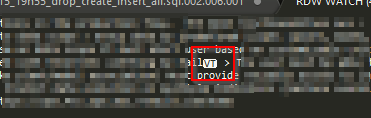
Je ne sais pas du tout à quoi correspond ce “vertical tabulation”,= (je connais le “horizontal tabulation” \u0009) mais visiblement il n’est pas apprécié quelque part dans la mécanique.
Le mieux est effectivement d’expliquer que Office et les pages Web en général (ce n’est sans doute pas spécifique à Simplicité) n’ont jamais fait bon ménage et que comme le dit @Francois quand on copie/colle entre Office te une page web il faut privilégier le Coller en texte brut (ça ne coûte pas un clic de plus)
Mais bon si on peut le remplacer par un bon CR à la volée c’est peut être pas plus mal…
Voilà le VT vintage à copier/coller dans un textarea ␋ =
ça fait bien planter le formulaire, le flux JSON reçu par le service get est illisible.
SyntaxError: Unexpected token in JSON at position 29899 at JSON.parse
C’est un caractère UTF-8 comme un autre, il n’y pas de raison de le filtrer, c’est la méthode JSONTool.jsonString qui ne gère pas bien l’encoding de ces caractères.
On va revoir cette méthode pour mieux encoder les String.