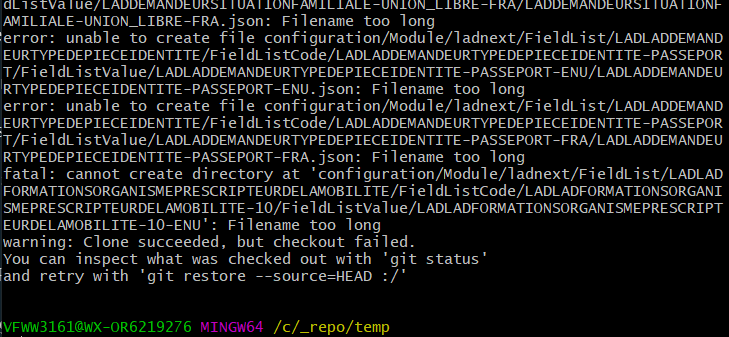
J’imagine aussi, si t’as un tgz à me transmettre je teste.
Pour la taille des nommages, ça ne me semble pas idéal de faire porter la responsabilité au designer qui a une courbe d’apprentissage déjà bien raide; ces bonnes pratiques doivent être policées par la plateforme, ce qui semble difficile sans limiter les cas récursifs comme les treeviews.
Je vois, techniquement, plusieurs pistes d’amélioration :
1) Redondances dans les nommages du mode explosé
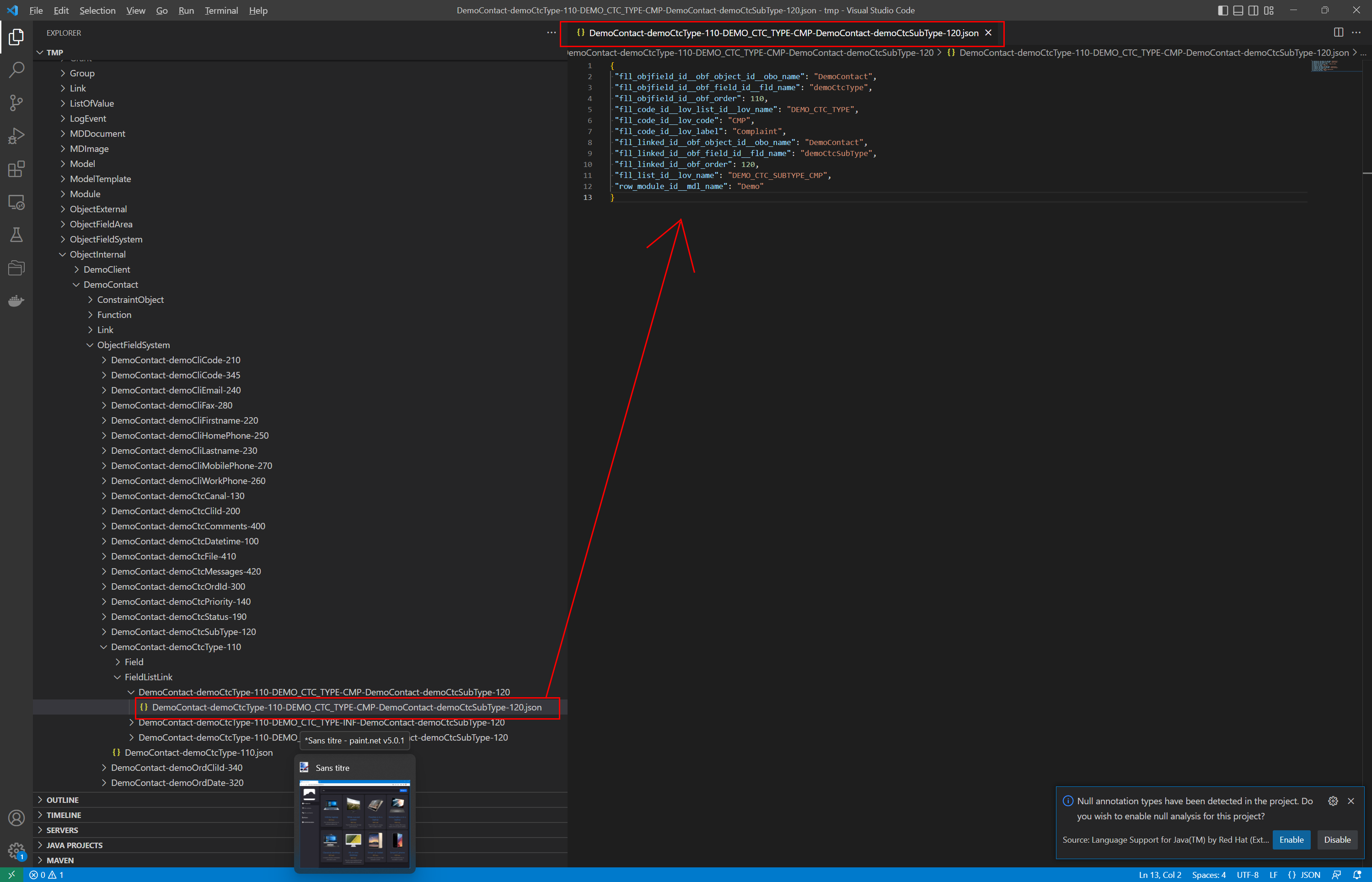
Le path d’export (et la lisibilité de l’arbre) pourrait être ~drastiquement~ réduit à de nombreux endroits avec un algo json<->xml un peu plus élaboré. Je mets un exemple, mais une lecture rapide permet de détecter des cas similaires un peu partout.
configuration/Module/OSI/FieldList/OSIEFFLUENTRESEAUPRIVE/FieldListCode/OSIEFFLUENTRESEAUPRIVE-EP/FieldListValue/OSIEFFLUENTRESEAUPRIVE-EP-ENU/OSIEFFLUENTRESEAUPRIVE-EP-ENU.json
config/Module/OSI/FieldList/OSIEFFLUENTRESEAUPRIVE/FieldListCode/EP/FieldListValue/ENU.json
PS: amha l’intérêt de cette évol niveau propreté et lisibilité de l’export dépasse la question de la taille du path.
2) Amélioration des recommandations de nommage et des nommages automatiques
SyntaxTool, systématisation de l’utilisation des trigrammes plutôt que des noms d’objet, nommages auto des NN, etc etc
config/Module/OSI/FieldList/OSIEFFLUENTRESEAUPRIVE/FieldListCode/EP/FieldListValue/ENU.json
config/Module/OSI/FieldList/OSIEFFRESEAUPRIVE/FieldListCode/EP/FieldListValue/ENU.json
3) Limitation de la taille des champs de configuration
no comment
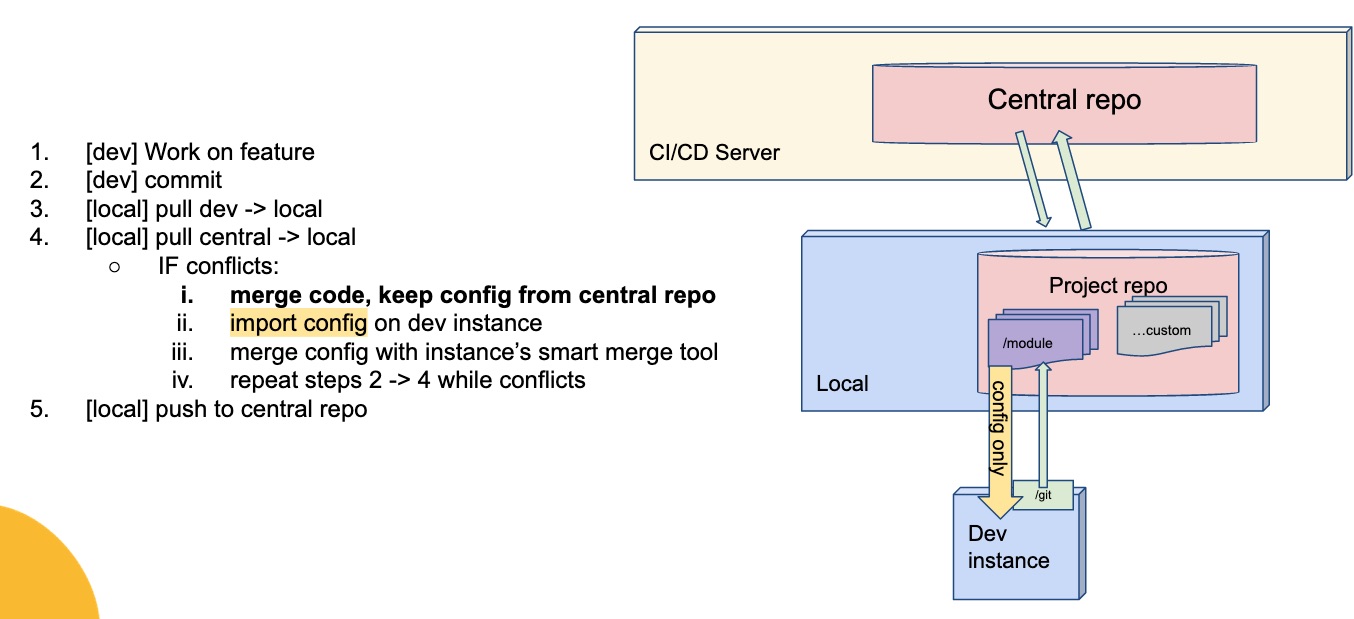
Ceci étant dit, ça ne résoud pas le problème de fond, qui est qu’on ne pourra jamais contrôler les cas récursifs comme le treeView, ce qui amène à une autre solution, qui a l’avantage d’être utilisable sans évol du socle la recommendation sur un process compatible avec un mode JSON ou XML non éclaté:
PS: J’ai à nouveau cherché les outils de diff & merge externes pour du XML / JSON et je ne trouve pas de solution élégante.
Dans ce mode-là, l’évol socle à considérer, qui est plus dans l’esprit simplicité, c’est de continuer à améliorer l’outil de merge, en splittant par exemple le merge de la conf en plusieurs étapes spécialisées, et un outil de merge de code au niveau du standard des outils git spécialisés.