Bonjour,
*** je vous communique les informations de version asap ***
Notre client AfterSales me remonte un cas curieux de conteneur Simplicité déployé sur GCP qui reboote de manière intempestive. La dernière log captée avant le reboot du conteneur est la suivante :
exception générée lors de l’appel à l’api /ui/json/app dont le détail est ci-dessous:
Ce symptôme ne me dit rien mais ça semble un pb d’écriture dans un file system lors d’une compilation.
La dernière méthode Simplicité appelée dans le stacktrace est le partialClearCache de l’objet système Adapter => cela correspond donc à l’enregistrement d’un item de paramétrage de type adapter, cet enregistrement déclenche la recompilation du code de cet adapter et visiblement c’est là que ça rencontre un pb d’écriture disque.
Je ne pense pas qu’il y ait un lien direct mais plutôt qu’il y a un pb plus général d’écriture disque qui provoque aussi un dysfonctionnement de Tomcat (qui a lui aussi besoin d’écrire des fichiers temporaires)
Sans savoir quelle est votre config de déploiement je ne peux pas avoir qui sature le disque et/ou s’il y a une limite/contrainte imposée par GCP à ce niveau mais en général ce sont les logs non purgées et/ou de fichiers d’import/export non purgés ou dans le genre
Il est possible de monter des volumes ou des file systems “temporaires”, cf. ce descripteur de déploiement docker-compose où tous les répertoires de travail (de Tomcat et de SImplicité) sont montés de cette manière, le container étant déployé, lui, en mode read-only (ce type de déploiement étant conforme aux exigences de l’ANSSI): docker/docker-compose-secure.yml at master · simplicitesoftware/docker · GitHub
Dans Tomcat ou dans Simplicité on ne verra que des symptômes de ressources manquantes, pas la cause de l’arrêt (pb de config, timeout, crash d’une ressource, arrêt par un collègue…).
A mon avis la stack est une conséquence du reboot/arrêt d’origine inconnue qui coupe les accès disques en faisant planter les derniers I/O de tomcat pas encore arrêté (thread en cours de compilation ici).
A voir si la log se confirme au même moment sur d’autres arrêts : compilation d’un Adapter ou autre code spécifique.
Merci beaucoup pour vos réponses.
Les pistes évoquées sont en cours d’analyse par nos équipes.
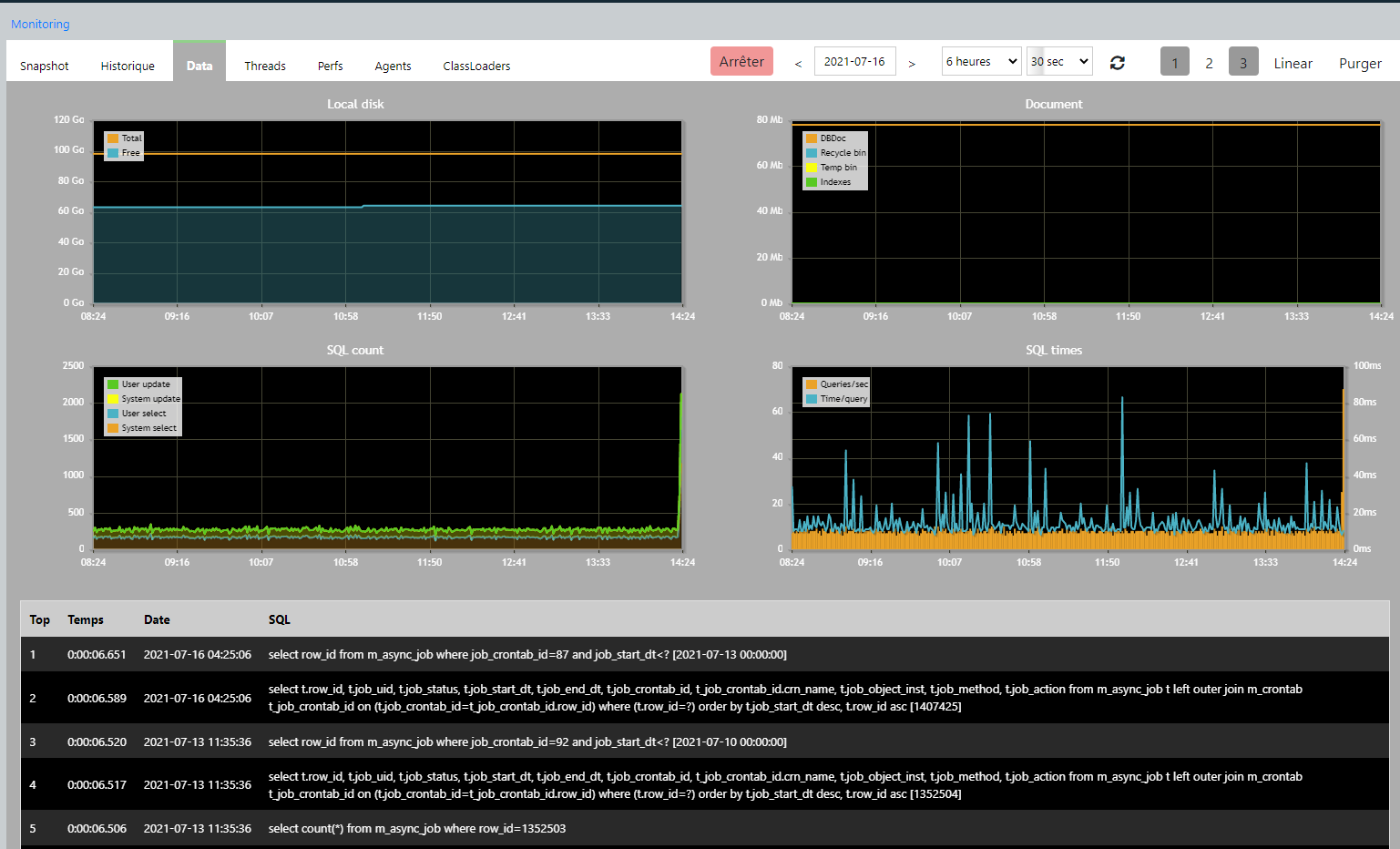
Autre précision: il s’agit en effet de traitements de chargement qui étaient très lents → il y a eu une action de redéfinition des index SQL sur les objets métier concernés de telle sorte que les traitements sont désormais beaucoup plus rapide à produire des logs et des rejets… on creuse du côté de la capacité disque allouée et sur la fréquence de remontée dans notre puit de logs (et purge des logs dans le conteneur)
ps: on m’a confirmé que le problème a été reproduit avec le dernier build à jour dans des conditions similaires.
Je ne sais pas trop comment les orchestrateurs gèrent les “tmpfs” mais fondamentalement c’est mieux de monter les espaces de travail de cette manière + des volume persistants bien dimensionnés pour ce qu’on veut garder (typiquement les logs) plutôt que de les faire écrire dans le file système du container.
Autrement dit, la stratégie imposée par l’ANSSI qui consiste démarrer le container en read only (et donc de monter des volumes ou des tmpfs sur tous les endroit où ça écrit) est donc à priori une bonne pratique. Attention, de mémoire, pour Simplicité ce n’est supporté qu’en version 5
Ci dessous les informations de la version :
Simplicité version5.0.56
Built on2021-07-13 14:39
Git inforelease/fdf6a680a4b546cb68dab65c2f37f9ec2abb65b0
Database level5;P00;48c942a06efd72d7c7a22dd32c5d97a7
Peut être un autre point intéressant (on ne sait jamais)
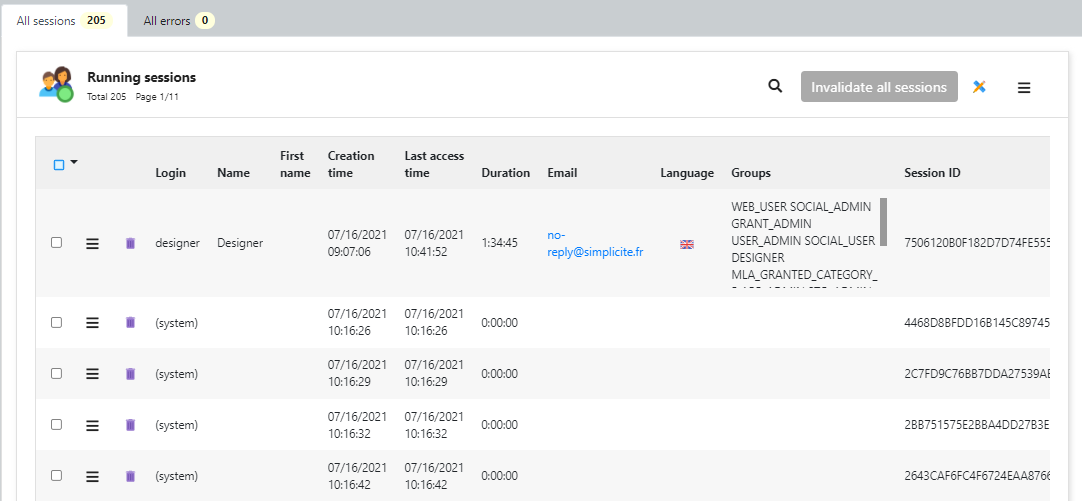
Je vois des session utilisateur se créer alors qu’il n’y a qu’un seul utilisateur connecté (designer).
On utilise l’utilitaire GrantAdmin pour faire certains appels lors du traitement de l’adapteur.
Enfin, on a fait une modification de configuration ce matin.
Le xms et le xmx du tomcat avait la même valeur dans les fichiers de configuration. Nous les avons modifiés (d’où notre heap à 100% sur nos post précédents)
Ca ne crée pas de session, c’est juste un accès base.
La liste des sessions regarde les sessions en mémoire et dit “(system)” si le Grant n’est plus chargé (pas d’accès au login ou aux responsabilités pour les afficher) = le logout normal appelle grant.destroy(), et fait un invalidate session qui devrait les retirer de cette liste (via listener tomcat SessionListener.sessionDestroyed).
Comme si des sessions n’expirent jamais / pas de timeout au niveau tomcat, ou d’invalidate session.
Il faut voir si elles finissent par disparaitre au timeout de session inactives.
La durée de ces sessions est de 0, ça ressemble plus à des accès API en masse sans cookie de session ou alors des ressources statiques non publiques… difficile d’analyser sans savoir qui fait des appels ni comment.
Merci, il faudrait également activer le Monitoring de Simplicité pour comparer la mémoire/heap, les threads de la JVM et l’espace disk vu de tomcat.
Tomcat a moins de 100 threads en général, pas 25k. Je pense que le graph sont des threads de processus sinon c’est que votre code contient des new Thread en boucle…
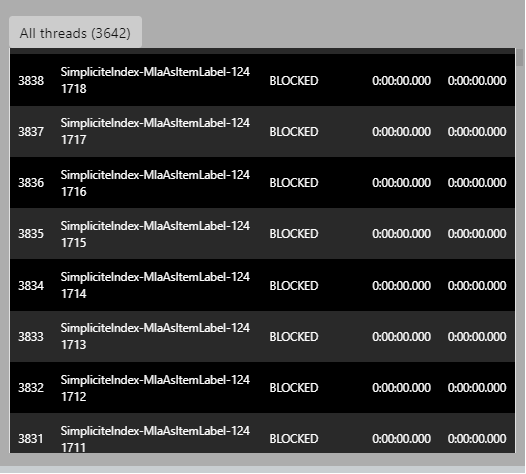
Simplicité utilise la conf tomcat = les threads partagés pour les sessions HTTP/AJP, et lance aussi des threads pour la cron ou les taches asynchrones dans un pool à taille fixe (1 daemon + 10 ou 20 workers). Tous les threads Simplicité commencent par “Simplicite-xxx” ils sont faciles à reconnaitre.
Ce sont des taches d’indexation des objets fulltext, massivement instanciées lors de votre import.
Ils sont bloqués puis dépilés par paquet qui dépend de la taille du pool (visiblement pas assez vite vue la montée en mémoire).
Pour éviter ça, il faut désactiver l’indexation fulltext lors de l’import puis faire une réindexation en masse à la fin.
Au début de l’adapter : passer le paramètre système USE_SEARCH_INDEX à non : setParameter("USE_SEARCH_INDEX", "no");
(dans le Grant qui lance l’import et/ou le singleton getSystemAdmin à voir)
faire les imports
A la fin le remettre setParameter("USE_SEARCH_INDEX", "sql");
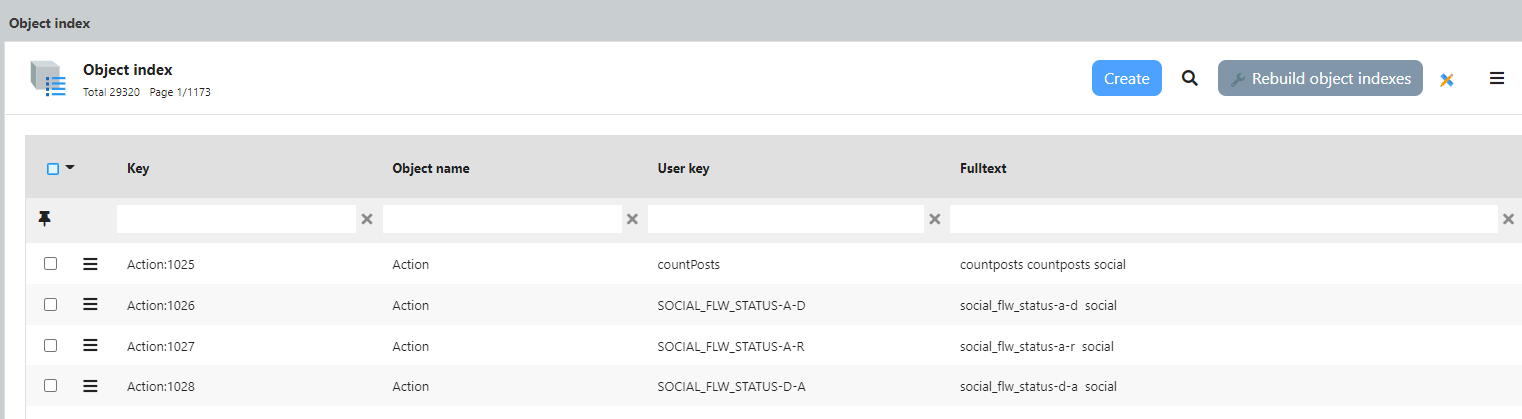
Refaire une indexation en masse de l’index : bouton action via UI ou via code invokeAction(“rebuildObjectIndex”) sur l’objet ObjectIndex
Oui surement,
Il faudrait voir comment on peut faire l’indexation en synchrone mais ça ralentira le temps d’import.
Le mieux dans tous les cas est de couper ce traitement et le remettre à la fin, comme on le fait aussi généralement pour les index non unique en base avec rebuild à la fin.
Normallement, le mode synchrone est forcé sur instances particulières :
private boolean isSyncModeForced(final ObjectDB obj)
{
// Synchronous mode is forced during platform initialization,
// on the I/O and Git endpoints and when using a batch object instance
return Platform.isInitializing()
|| obj.getGrant().isIOEndpoint() || obj.getGrant().isGitEndpoint()
|| obj.isBatchInstance();
}
Vous devez utilisez d’autres instances.
Une autre approche est de dire obj.setIndexable(false) sur les instances d’objets utilisée par l’adapteur (dans le code de l’adapter ou dans le postLoad de l’instance particulière). Avec toujours un rebuild à la fin.