Je souhaite créer une vue filtrée dans mon objet qui affiche :
les enregistrements créés par l’utilisateur connecté
ou dont il est contributeur (via les colonnes legal_text_person_id, legal_text_publisher_id, ou des champs texte comme legal_text_juridique_contributor, legal_text_business_contributor qui peuvent contenir plusieurs row_id séparés par ;)
et également ses favoris, même s’il n’est pas contributeur ni créateur.
Pour les contributeurs et créateurs, voici le filtre SQL que j’utilise dans le champ Filtre additionnel SQL (vwi_search_spec) :
(
t.created_by = [LOGIN]
OR t.legal_text_person_id = [USERID]
OR t.legal_text_publisher_id = [USERID]
OR t.legal_text_juridique_contributor LIKE CONCAT('%', [USERID], '%')
OR t.legal_text_business_contributor LIKE CONCAT('%', [USERID], '%')
)
Ce filtre fonctionne correctement.
Problème :
Je voudrais ajouter les favoris de l’utilisateur même si le record ne correspond pas aux critères ci-dessus.
Or :
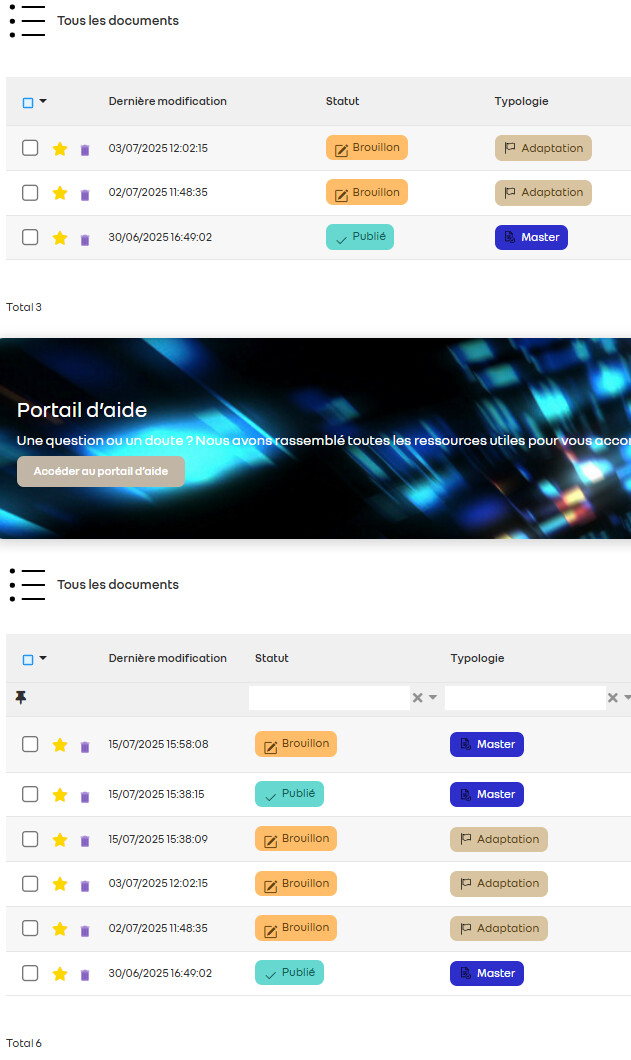
Les favoris ne sont pas stockés dans les colonnes de l’objet
Ils sont gérés côté UI, via les préférences utilisateurs (icône étoile)
Et comme vu dans les paramètres utilisateur, chaque vue d’accueil a ses propres favoris
Cette syntaxe me semble invalide car LOGIN est un String donc plutôt à mettre entre quote, mais peut être que le parser est malin et les ajoute en escapant le login en SQL.
t.created_by = '[LOGIN]'
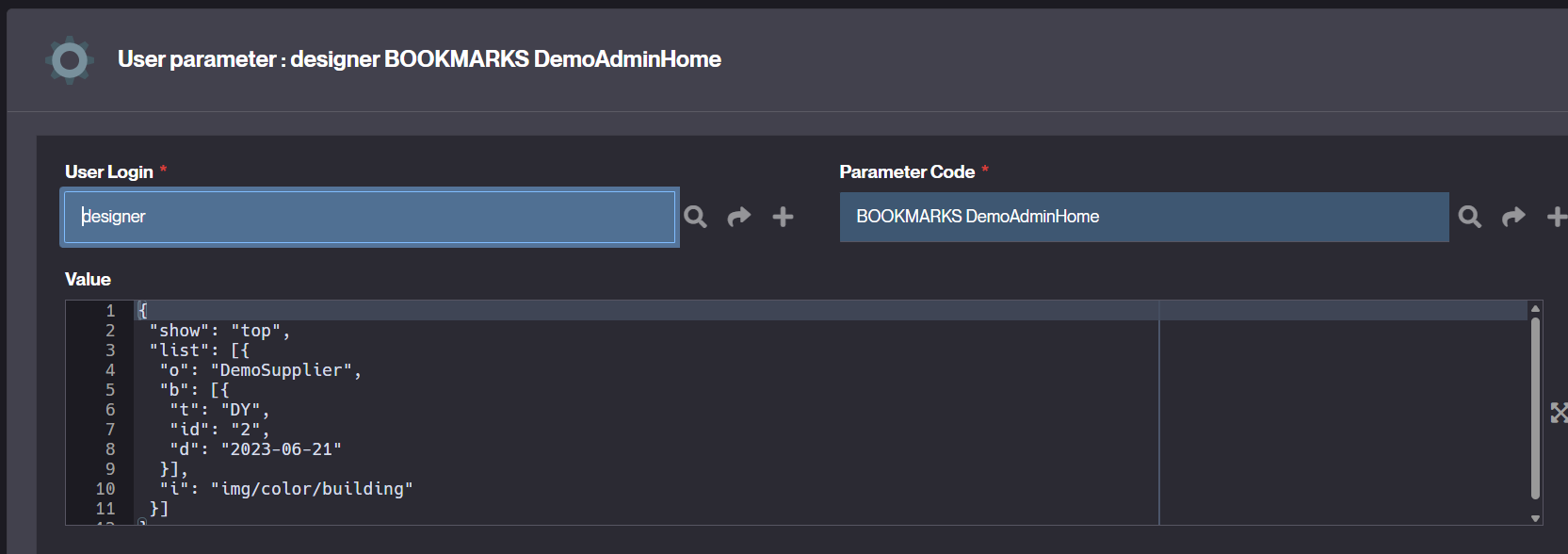
Sinon pour avoir les bookmarks, ils sont persistés en base au niveau des paramètres du User par scope/accueil, et monté en session dans un objet JSON qu’on peut convertir en SQL
nous nous sommes focalisés sur le JSON en param et la table d’association et le filtre SQL suivant ramène exactement les filtres ainsi que les favoris lié.
Voici la version fonctionnelle du filtre complet, avec tous les cas :
filtre complet
(
t.created_by = '[LOGIN]'
OR t.legal_text_person_id = '[USERID]'
OR t.legal_text_publisher_id = '[USERID]'
OR EXISTS (
SELECT 1 FROM lbc_legal_text_person_business pb
WHERE pb.legal_text_id_person_business = t.row_id
AND pb.legal_text_person_business_id = [USERID]
)
OR EXISTS (
SELECT 1 FROM lbc_legal_text_person_juridical pj
WHERE pj.legal_text_id_person_juridical = t.row_id
AND pj.legal_text_person_juridical_id = [USERID]
)
OR t.row_id IN (
SELECT (b_elem->>'id')::int AS id
FROM (
SELECT jsonb_array_elements(json_val->'list') AS list_elem
FROM (
SELECT usp_value::jsonb AS json_val
FROM m_user_sysparam
WHERE usp_user_id = [USERID]
AND usp_param_id = (
SELECT row_id
FROM m_system
WHERE sys_code = 'BOOKMARKS LBCHomeUser'
)
) sub
) parsed,
jsonb_array_elements(list_elem->'b') AS b_elem
WHERE list_elem->>'o' = 'LbcLegalText'
)
)
Nous avons suivi votre recommandation sur l’abandon des colonnes contenant des row_id concaténés en remplacant cela par les deux vraies tables de jointure, c’est beaucoup plus propre et sécurisé.
Cette solution fonctionne parfaitement maintenant, et la vue ramène à la fois les contributeurs, les auteurs et les favoris.
Bravo, parser le JSON en SQL c’est balaise et assez original !
Mais cela n’est pas transposable sur d’autres SGBD.
Personnellement quand c’est complexe je préfère faire du java et placer les filtres en SQL “standard” par code au postLoad en fonction du nom de l’instance dans ma vue.
Les FK sont des integer en base, donc ce n’est pas utile de mettre des quotes / et ça peut provoquer des erreurs de cast implicite car PGSQL est généralement assez strict sur les types des colonnes comparées.
 Pour les contributeurs et créateurs, voici le filtre SQL que j’utilise dans le champ
Pour les contributeurs et créateurs, voici le filtre SQL que j’utilise dans le champ 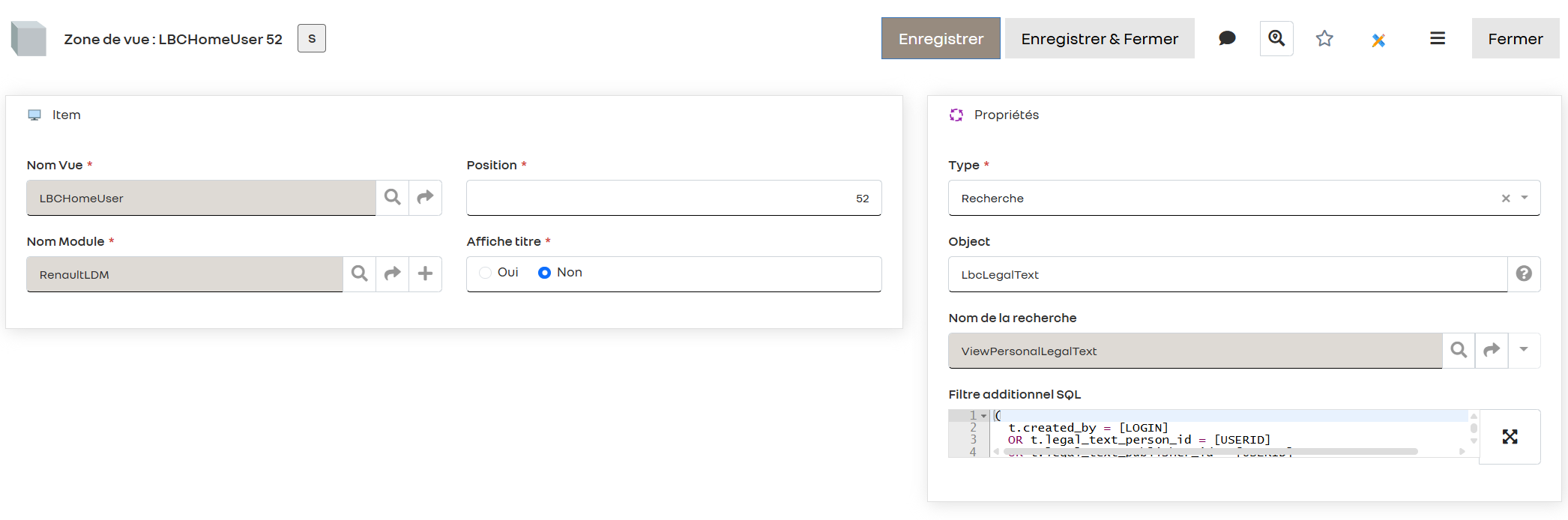
 Problème :
Problème : Voici ce que je constate :
Voici ce que je constate :