Bonjour,
la période de Noël approchant, je tente ma chance…
Est-il envisageable que le socle Simplicité gère la persistance des données collectées dans le contexte des objets service-simplicité ?
Sans trop détailler, il s’agirait de pouvoir activer une fonction de copie/cache des données sur l’instance Simplicité consommatrice (a minima les champs clés et le row_id, et éventuellement d’autres champs de l’objet distant) de telle sorte que la copie de l’objet puisse être opérée “comme si l’objet était local” (mise en relation via des fk, présentation en pillbox, etc., recherches étendues aux propriétés liées, …).
Et comme je promets d’être sage et de finir les upgrade en 5.1 de toutes mes instances avant la fin de l’année, je vise la Lune : si en plus les stratégies de resynchro (en masse ou selon le journal de modifications éventuellement disponible sur l’instance hébergeant la référence) pouvaient être activées selon les besoins, ce serait génial!
Dans ce cas on est plus dans une recopie “batch” régulière des données que dans un objet “service” a proprement parler
Si le volume des données à répliquer n’est pas énorme ça peut se mettre en place facilement en paramétrant un objet à persistance locale et en le chargeant (totalement ou partiellement, par cron ou “à la demande”) via un search sur l’objet service (celui-ci n’étant pas accessible directement)
Le cas général d’un objet service “mixte” qui stockerait localement tout ou partie des données localement pour se présenter comme un objet local tout en étant un objet service est forcément complexe. Je pense qu’il est plus simple de gérer spécifiquement des cas simples que de vouloir gérer de manière générique les cas généraux.
Si les données sont juste des catalogues de données (sans autre FK en cascade…) un système de réplication des objets à J-1 est une bonne approche.
Il faut mettre les définitions des objets en commun dans un module à installer partout.
Ou alors créer des versions remote/simplifiées des objets distants synchronisés avec un action de synchro par cron, et les utiliser comme des objets locaux.
J’ai déjà fait cela dans un système où on devait avoir des infos client le temps de traitement d’un dossier et les supprimer à la fin du processus = pour des raisons de découplage front/back entre systèmes donc avec des données copiées localement (mais pas synchronisée car détruite à la fin du processus de quelques jours).
Ce que tu vas faire pour certains objets me semble généralisable.
Le père-noël (qui habite à la cave) me chuchote que ton sujet est très intéressant car le besoin revient souvent dans une architecture distribuée. Il faudrait avoir des objets services persistants.
recopie locale des meta-data + création de la table via les mécanismes usuels
syncho périodique des données modifiées (diff sql ou via redolog)
limite : si l’objet référence d’autres objets distant “non service”, le lien ne sera pas copié
sinon on peut très bien imaginer remonter un modèle relationnel à charger dans l’ordre des dépendances.
ce serait du polling périodique, sinon on peut aussi voir comment un objet “master” pourrait faire du push au fil de l’eau (asynchrone) vers des instances “abonnées”, ce qui serait une autre approche plus propre (le polling global serait une sécurité en cas de pb de synchro unitaire).
On peut prévoir ça dans la 5.3 car la 5.2 va passer en release candidate sous peu.
Après analyse, des objets service mixtes (distant + local) seraient difficilement compatibles ascendants, à date ce sont des appels de services distants. Implémenter un “search” qui ferait une recherche locale+distante ne semble pas très performent non plus, de même recréer des ID/FK persistants en local par rapport aux clés fonctionnelles reviendrait à réinventer ce qu’un objet interne sait déjà faire.
De mon point de vue, il serait plus simple de laisser les objets (web)service faire leur job, et d’avoir une autre approche pour ce besoin de “réplication” d’objets entre applications disjointes :
Avoir un même modèle/module métier (objets + fields + links) installé sur N applications :
vu de chaque application, les objets ont une persistance locale = internal object + FK…
ça évite de synchroniser le meta-modèle au runtime
Et définir une surcouche pour définir qui serait maitre et/ou abonné entre les applications de ces objets.
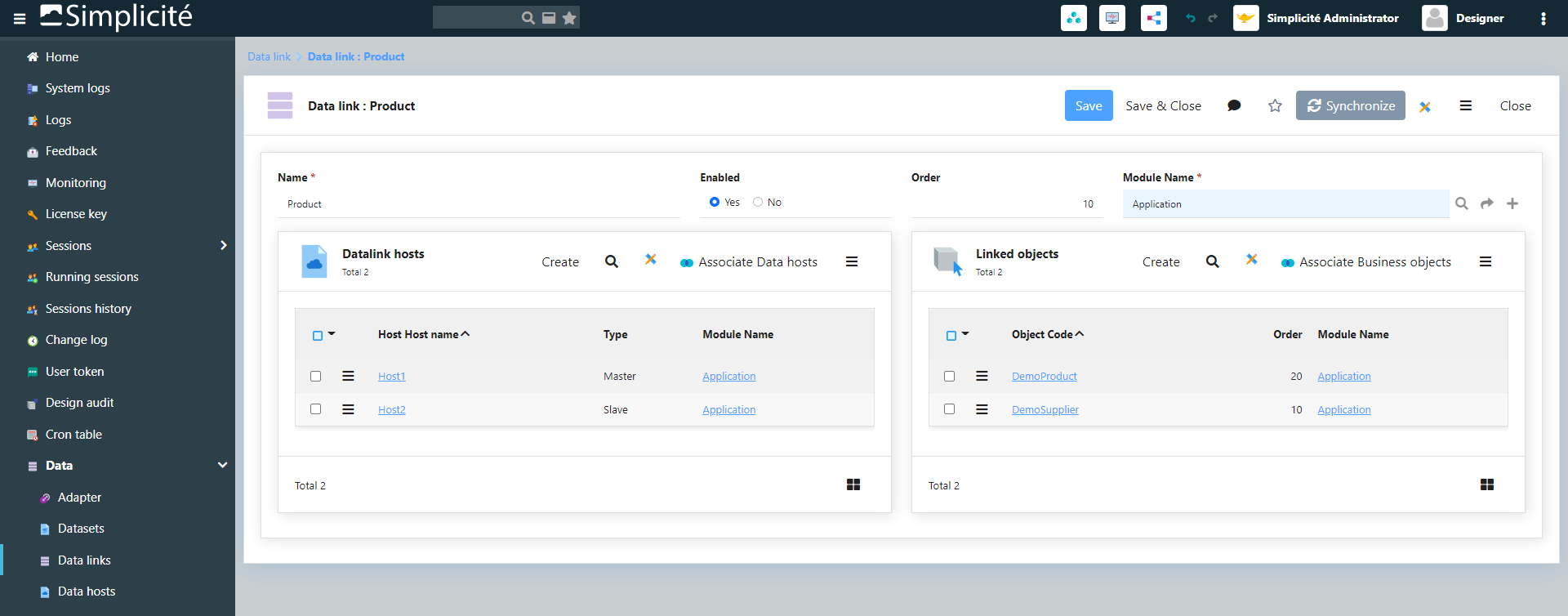
On aurait alors besoin de créer une nouvelle notion de DataLink dans Simplicité, un DataLink serait définit avec :
Un nom unique et un module
Une liste d’applications (URL, credentials I/O, encoding…) : on peut réutiliser les Paramètres systèmes mis en place dans le cadre des objets service (et ajouter la notion de “qui est master/slave”).
Une liste d’objets répliqués avec des options de synchro (mode push master=>slaves, mode pull slaves<=master avec fréquence de resynchro, limiter les fields de certains objets…)
Au runtime :
Mode Push / fil de l’eau
Quand une application démarre, elle liste ses master DataLinks pour les avertir de se faire notifier au fil de l’eau des mises à jour (push), et quand elle s’arrête elle se désinscrit.
Quand une donnée master est modifiée, une tache asynchrone notifie tous les abonnés (best effort ou log des rejets pour rejeu…).
Mode Pull / batch
Périodiquement en fonction d’une fréquence définie dans le DataLink, un batch sur chaque application abonnée fait un search paginé et synchronise ses tables locales, l’application maitre peut se reposer.
Il faudrait que les row_id des objets répliqués soient identiques pour éviter d’ajouter un “row_id_master” = en cas de changement de clé fonctionnelle d’une ligne, il faudrait se rappeler de quel ID il s’agissait pour éviter de supprimer+recréer (perdre des liens) au lieu de simplement modifier la clé fonctionnelle
le mode pull serait obligatoire pour rattrapage des échecs via “push” ou suite à import en masse sur le master
le timestamp updated_dt pourrait aussi servir pour la synchro du “delta” uniquement en persistant la date de dernière synchro par application
@bmo as tu des remarques ? est ce que ça pourrait convenir à vos besoins de référentiels dupliqués ?
OK pour l’approche tirée par le partage d’un sous-modèle : ça permettra en l’occurrence de garantir que les hypothèses de lotissement sont complètement à la main du métier (i.e. intégration dans un module dédié partagé entre plusieurs périmètres/instances). Les objets en question constituant un modèle d’échange entre les instances.
Il faudra être particulièrement vigilants sur la non-dépendance de la configuration du modèle d’échange (ce module devra être autonome. Seules les modèles ré-utilisateurs devraient pouvoir le référencer. Ce point pourait justifier un check de la plateforme pour un type de module particulier (“Partagé” par exemple) qui ne devra dépendre de rien (ou éventuellement d’autres modules partagés).
Concernant les caractéristiques du concept de DataLink, si j’ai bien compris ça fera le job…
Je crois comprendre aussi que la synchronisation (ou la corrélation) des row_id entre le master et les slaves n’est pas triviale. La création et la suppression sur un des slaves ne devraient-elle pas obligatoirement être synchrones vis à vis du master ?
PS1: J’ai déjà un cas d’usage dans mon portefeuille de dette donc je suis complètement motivé pour tester …
PS2: comme promis, j’ai été sage et j’ai terminé l’upgrade de mes instances en 5.1 avant la fin de l’année
[EDIT] J’ai relu les échanges précédents et en effet, on parle bien de la 5.3 au plus tôt… il va donc falloir que je sois sage aussi en déployant rapidement la 5.2…
Oui il faut bien séparer le design métier des objets partagés / de la configuration des accès/réplications entre applications.
On peut effectivement rendre synchrone les mises à jour si les systèmes abonnés répondent rapidement = il faut diffuser les data+row_id comités sur master et on peut imaginer un message différent pour indiquer quelles applications ont été mises à jour en cascade.
Quand je dis asynchrone c’est que la synchro n’est pas en temps réel mais au fil de l’eau (pas de commit transactionnel entre N bases), soit dès la mise à jour du master ou plus tard si indisponible par resynchro.
Un autre point de conception sur les droits de mise à jour
Dans l’idée la mise à jour UI autorisée sur le master / interdite sur les autres : là je sais pas trop s’il faudra le contraindre en dur ou laisser un système de droit paramétrable (responsabilité CRUD sur master, R sur les autres), typiquement si une partie du modèle n’est pas répliqué (champs étendus/héritage sur un abonné à ne pas écraser et à laisser modifiable…)
L’accès I/O ou API devra lui permettre la mise à jour.
On va commencer à avancer avec cette conception générale en 5.3.
Sur ce point, si on peut reconduire le mode de fonctionnement des service-simplicite qui permet de CRUD depuis le slave (si habilité dans le slave) c’est l’idéal .
si on met à jour une donnée publiée par un master, on risque de la perdre à la prochaine mise à jour depuis le master.
ou alors tu es plutôt sur une approche ou tout le monde est maitre/esclave ?
Dans mon idée initiale, une application est maitre et/ou esclave par paramétrage.
Donc rien n’empêche que tout le monde soit maitre (CRUD) et esclave pour être notifié de tout le monde. Se posera alors le pb de concurrence d’accès à un instant t sur 2 masters, le dernier aura forcement raison.
Sinon, il faut définir quand on veut s’abonner aux mises à jour ou pas si on permet de modifications locales = recopie à la demande.
Si ça peut fonctionner comme ça alors ça me semble correspondre au besoin.
Dans la plupart des cas, il n’y a qu’un master et une réutilisation de la donnée sans modification.
Dans d’autres, quelques systèmes pourront contribuer à documenter une liste de référence dans un MDM (“master” au sens fonctionnel, unique par construction). Si techniquement, il faut que ces systèmes (bien identifiés) soient configurés techniquement comme “master” pour que les mécanismes de notification / synchronisation vers le MDM s’appliquent, alors ça fera ce dont on a besoin.
Et en effet, il y aura toujours à la marge le cas des mise à jour concurrentes (mais c’est déjà le cas en multi-édition/usage des objets métier sur la même instance) → la cerise sur le gâteau serait que l’ouverture d’un formulaire sur un noeud “master” notifie les “slaves” de l’usage de l’objet. Ainsi, si un record est ouvert en même temps sur deux instances “master”, chacun sera notifié de l’ouverture du record par l’autre.
Ok compris, on est plus sur un besoin d’enrichissement de la donnée, chaque applicatif est maitre d’une partie des objets et/ou champs des objets.
Il faudra plutôt pouvoir spécifier plus finement (au niveau champ et pas qu’au niveau objet) qui est maitre pour éviter tout pb de concurrence sur la cerise. A suivre…
Objets et DataLinks à configurer dans des modules à installer sur chaque application
Toutes les applications peuvent être master ou slave pour chaque datalink (slave = reçoit juste les données et ne postera rien)
Il faut que les hosts soient nommés = identifiables pour savoir se reconnaitre et ne pas s’appeler eux-mêmes par exemple (donc forcer un nom Globals.set/getApplicationName() ou un URL set/getApplicationURL() ou via paramètre système DIRECT_URL or SERVER_URL)
Tout passe par la couche standard de service REST
Au démarrage tomcat, on voit les master/slave chargés dans les logs
Seuls les champs qui matchent entre les objets sont valorisés, une application peut ajouter ses propres champs “locaux” à l’objet (sinon via héritage classique pour factoriser dans un module commun les objets synchronisés partout)
Les tables des datalinks sont synchronisées avec les même row_id, pour éviter de gérer des tables de mapping d’id
Les mises à jour sur un master sont propagées partout au save/delete (aux autres masters ou slaves avec test de non bouclage infini si N masters)
Si un host est injoignable, une tache cron (par polling) resychronise en masse depuis la date de dernière mise à jour (stockée via param système pour chercher tout depuis la colonne last updated_dt, et si pas de timestamp ça fera un fullscan)
Tout cela reste désormais à tester/roder et surement améliorer mais le principe général est en place.

 …
…