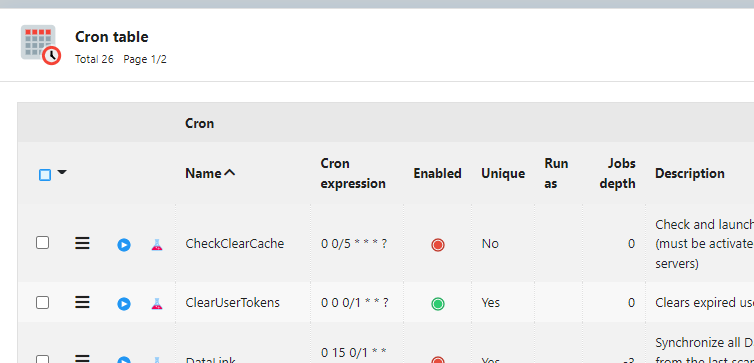
On constate qu’en environnement multi instance la modification de paramètrage de CRON n’est pas propagée. Y’a-t-il une configuration supplémentaire à faire pour que ces changements soient propagés à chaud sur les autres instances simplicité ?
Aussi, comment s’assurer que le CRON ne se lance qu’une seule fois et pas sur chaque instance ?
La paramétrage des cron est en base donc nécessairement partagée si on redémarre les cron.
Si vos noeuds communiquent entre eux (comme pour un clear cache) les cron redémarreront toutes automatiquement via /io. Sinon vous devrez faire un restart de la cron de chaque noeud.
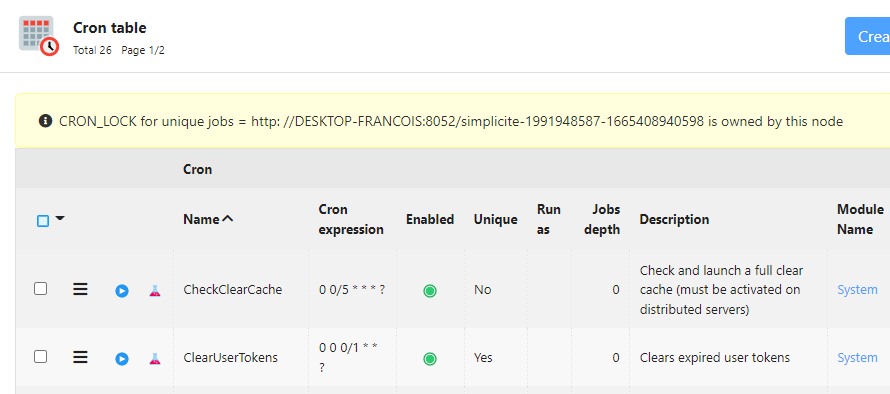
Le premier noeud qui démarre pose un verrou CRON_LOCK (cf en base dans la table des sys param et la liste de vos noeuds dans Operation). Il aura la charge d’exécuter les Cron de type “Unique” typiquement pour ne faire l’action qu’une seule fois : traitement de masse sur les données en base tous les jours…
Si l’action de cron est non unique, elle est lancée sur chaque noeud = pour la purge de log locale, garbage mémoire…
On a eu la surprise la semaine dernière. Nous avons 4 instances, nous avons désactivé le CRON sur une instance mais, le CRON à continuer a se déclencher sur les 3 autres instance.
Par ailleurs, même si le cron est unique, il s’est visiblement déclenché 3x par jour à la même heure. Ou alors il manque une information comme quoi il a été effectif qu’une seule fois sur les 3.
Vous devez vous assurer que vos service IO sont ouverts entre les URL de vos noeuds, que contient la table PlatformNode / m_pf_node ?
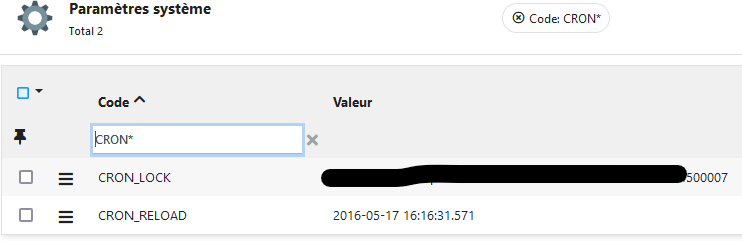
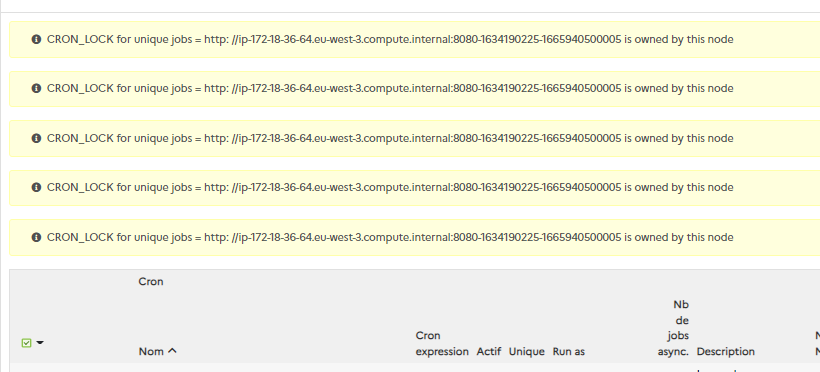
Que vaut le paramètre système CRON_LOCK quand tout est démarré ?
Mettez une trace applicative dans votre traitement pour identifier s’il est tracé/lancé 3 fois ?
La log des trigger indique que la cron se réveille mais effectivement l’action n’est pas forcement appelée.
Si cela se reproduit on devra refaire des tests avec la même configuration pour voir ce qui se passe.
Vous parlez d’une tache en particulier, pas de toute la cron ?
Il est nécessaire que les cron fonctionnent partout, pour exécuter les taches non uniques.
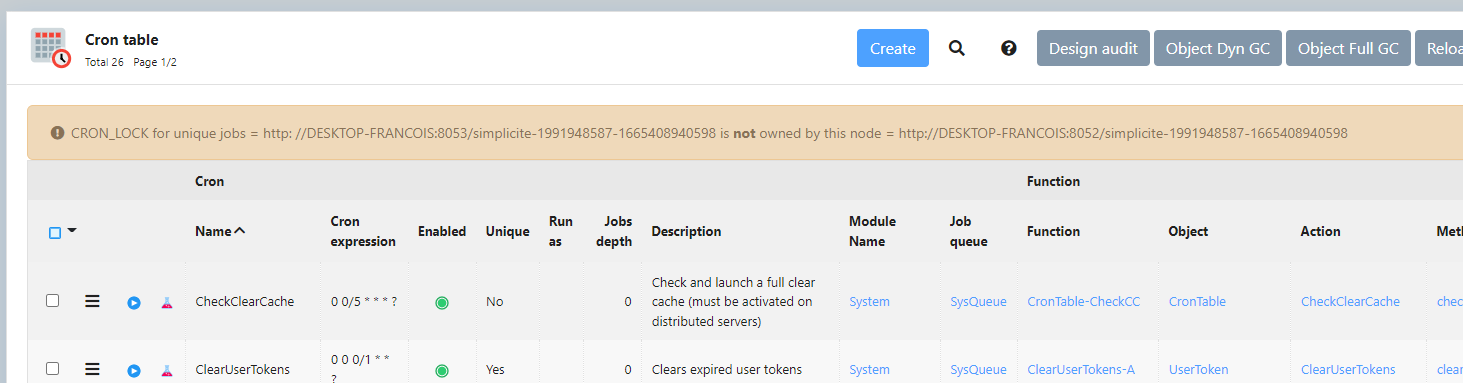
L’url dans le CRON_LOCK n’a rien a voir avec les 4 URL présentes dans endpoints des noeuds, est-ce normal ?
Mettez une trace applicative dans votre traitement pour identifier s’il est tracé/lancé 3 fois ? La log des trigger indique que la cron se réveille mais effectivement l’action n’est pas forcement appelée.
Ici, ce sont des logs placé dans l’action associée au cron. Quand on regarde les heures de déclenchement, on dirait que le LOCK est bien en place, mais il ne fait qu’empecher le déclenchement paralèlle et ne limite pas le déclenchement à 1 seule fois.
Oui le verrou n’est pas une URL mais correspond au timestamp compliqué mis en mémoire de celui qui l’écrit en base. Aucune chance qu’un autre node ait le même.
La date CRON_RELOAD est positionnée par le noeud qui a relancé/rechargé toute la CRON (via action curl ou bouton recharger). Il permet via un job de relancer les CRON de chaque serveur (en fallback lorsque la couche IO ne fonctionne pas, comme pour le clear cache). Cette tache est peut être arrêtée chez vous.
J’ai l’impression que vos jobs se lancent 3 fois mais sur un seul noeud : c’est plus un “synchronized” sur la JVM (sur la méthode ou les grant ou l’objet…) qui les exécutent en séquence. Aucune chance que 3 JVM lancent le job à 3 horaires différents si ce Job est à heure fixe.
Essayez de tracer “qui” lance le job via un AppLog.info de Platform.getEndPointURL() ou éventuellement Platform.getEndPointIP() si différent de 127.0.0.1.
Merci de nous donner la définition exacte de votre job car les horaires ont l’air étrange.
Ré-ouvert.
Pour donner suite à ce post qui n’est pas résolu dans votre configuration en production :
Le paramètre system CRON_LOCK identifie le noeud qui a lancé le premier une tache unique
Le CRON_LOCK peut/doit être supprimé manuellement s’il ne correspond à aucune URL connue ou en cas d’arrêt brutal de celui qui avait posé ce verrou. Il sera réattribué au premier noeud qui trouvera une tache UNIQUE à traiter.
Si votre tache UNIQUE se lance sur plusieurs noeuds, c’est qu’une de vos procédures d’exploitation fait que le verrou change de main (suite par exemple à un reload forcé à chaud sur un noeud).
Dans un 1er temps en 5.1
Il faut supprimer le CRON_LOCK (on va aussi vérifier si on ne livre pas à tord avec une mauvaise valeur dans nos builds docker)
Arrêter le cluster proprement (pas de kill -9), une instance qui s’arrete proprement = arrete sa cron et ses threads, libère le CRON_LOCK, se retire de la liste des nodes démarrés, etc.
Démarrer 1 seul noeud, et attendre qu’il prenne la main (regarder le paramètre CRON_LOCK dans les param systèmes)
Puis lancer les autres noeuds, et vérifier que le CRON_LOCK reste bien affecté au premier noeud démarré.
Ensuite il faut éviter/prohiber de créer/modifier/recharger des cron à chaud si la communication entre noeuds se fait mal. En 5.1 le noeud qui reload la cron, prend également le CRON_LOCK, ce qui pourrait expliquer que plusieurs noeuds pensaient être les propriétaires des taches uniques à un instant t (le temps que l’information se propage en synchrone ou par cron entre les noeuds).
Dans un second temps
On va livrer une évolution pour que l’action Reload depuis la liste de la Crontab demande à l’utilisateur si le noeud doit prendre la main en forçant le CRON_LOCK. Ca évitera de l’écraser sans le savoir, ou de le forcer à la demande si on a eu un crash serveur.
Quoi qu’il en soit, en terme d’architecture, il conviendrait de dédier un noeud aux taches uniques et qu’il ne soit pas load-balancé pour les accès UI, en général ce n’est pas les mêmes SLA/QoS en terme CPU/mémoire/horaires de service… et il faut éviter de perturber les accès web avec des traitements batchs en masse avec une autre URL (pour voir les logs des batchs toujours au même endroit, forcer le CRON_LOCK uniquement sur ce noeud…).
Cron CheckClearCache
Dernier point, en mode cluster il est très important de lancer la tache CheckClearCache car celle-ci assure le “ramasse miette” des actions synchrones qui n’auraient pas pu être envoyées via la couche IO entre les noeuds à savoir:
S’assurer que chaque noeud est dans la table des noeuds démarrés
S’assurer si un clear-cache a été réalisé sur un noeud (qui pose un timestamp LAST_CLEAR_CACHE en base)
Déconnecter des users ayant perdu leurs droits (forcer le logout partout pour tuer toutes ses sessions éventuelles sur les noeuds du cluster)
Redémarrer la cron si ce n’est pas déjà fait (timestamp dans le param CRON_RELOAD)
Cette cron est livrée arrêtée par défaut car on est rarement en cluster.
Nous allons livrer quelques évolutions pour renforcer la mécanique du verrouillage des taches uniques par un noeud. Sans visibilité sur vos travaux, on va devoir backporter temporairement le traitement en 5.1 qui n’est normalement plus maintenue depuis fin septembre.
Au moment de voir si un node possède le verrou s’il y a une tache UNIQUE à lancer, on va ajouter des tests de robustesse :
si le verrou est expiré / pb de timestamp suite à un arrêt anormal de l’instance qui possédait le verrou, le node qui le possédait se le réaffecte en priorité s’il n’a pas déjà été repris (même end-point)
si un node n’est pas le propriétaire du verrou, il va tout de même faire un test que celui qui le possède est toujours en vie (appel du service /ping sur le end-point du CRON_LOCK). Si le ping ne répond pas au bout de 5 secondes (c’est un service sans authent et très rapide), il se réaffectera le verrou
Si plusieurs nodes constatent que le propriétaire ne répond pas, le premier pris au hasard reprendra le verrou
Livraison à suivre quand nous aurons fait des tests de robustesse à ce niveau, ce qui pourra prendre quelques jours.
Ok, pour info de notre coté on maintien en attendant la solution de downscaling à 1 instance la nuit pour éviter les multiples déclenchements. De plus, économiquement et écologiquement parlant c’est plus intéressant donc c’est peut être la solution définitive qui sera retenue.
De notre coté on ne traite plus trop ce sujet, ayant une problématique d’authentification Azure plus urgente.
Super, merci pour ces évolutions qui permettent d’y voir plus clair !
Nous sommes en train de tester cette version en preprod.
Çà a l’air de bien fonctionner en mono instance. On a cependant 4 crons qui n’ont pas tourné cette nuit entre minuit et 5h Voici les pistes d’analyses explorées :
Coupure de la plateforme pendant la nuit → A priori non car le autres ont bien tourné 0h00 → KO
1h00 → OK 2h00 → KO 3h30 → KO
3h45 → OK
4h00 → OK
4h30 → OK 5h00 → KO
5h15 → OK
Aucune trace dans les logs de planification ou exécution, je continue à chercher
Les définitions des crons étaient bonnes, toutes validées grâce au testeur d’expressions cron embarqué.
Nous avions touché aux crons dynGC et full GC, je les ai rétabli à la fréquence par défaut:
Tous les crons system Log* étaient activés, je sais pas si c’est une erreur de notre part, mais je les ai tous désactivé car ça rend l’analyse des logs pénible
A main levé comme ça auriez-vous d’autre hypothèses ? Merci d’avance!
Pour info, certains de ces crons tournent déja en prod sans problème et j’ai testé de forcer l’execution de ces crons ce matin et ils ont abouti.
En marge de tout cela, j’ai remarqué que quand on change de page le message (certes très utile) s’empile mais ce n’est pas gênant, suffit de rafraichir pour reset les messages
Vos heures de passage sont étranges, du moins la périodicité n’est pas constante.
Merci de préciser les définitions des jobs OK et KO : expression + unique ou pas ?
pour qu’on essaye d’analyser ce qui pourrait poser problème.
Les cron Log* sont celles du monitoring.
Pour les arrêter ensemble, il suffit de faire “STOP” sur l’écran de monitoring. Sinon le monitoring ne va surement rien comprendre.
N’arrêtez pas un job Simplicité si vous ne savez pas à quoi il sert. les “GC” vident la mémoire régulièrement des objets non utilisés en session depuis un certain temps.
On va corriger le message qui se répète, le contexte ne doit pas bien se réinitialiser à chaque liste.
Nous avons une quinzaine de CRON différents qui se délenchent une fois par nuit. Vous comprendrez en voyant la liste complète.
Les cron Log* sont celles du monitoring.
Pour les arrêter ensemble, il suffit de faire “STOP” sur l’écran de monitoring. Sinon le monitoring ne va surement rien comprendre.
→ D’accord, je ne savais pas que ça correspondait aux logs de monitoring. On a du lancer le monitoring une fois mais on ne se sert pas trop de cette fonctionalité
N’arrêtez pas un job Simplicité si vous ne savez pas à quoi il sert. les “GC” vident la mémoire régulièrement des objets non utilisés en session depuis un certain temps.
→ Nous avions augmenté la fréquence des GC pour debuguer des traitements asynchrones, en aucun cas on les a désactivé.
Rien d’anormal dans vos déclarations.
Vous êtes les seuls à avoir ce genre de pb de cron, mais les seuls aussi à rester en 5.1 donc on va devoir investiguer sur cette version qui a peut être qq chose d’anormal.
Quand elles sont à heures fixes on les paramètre comme ceci : 0 15 6 * * ?
mais la dernière étoile (l’année) doit être optionnelle.
Si certains jobs se lancent et pas d’autres, il faut voir ce que raconte les logs pour cerner le pb :
le demon Simplicité tourne correctement sinon rien ne se lancerait, et on aurait vu le problème depuis longtemps
serait ce le composant Quartz qui calcule mal les heures/prochains passages ?
ou l’action qui ne fait rien même si elle est appelée (verrou applicatif, filtre, runAs non habilité…) ?
Les logs Simplicité indiquent le temps d’endormissement du demon jusqu’aux prochaines taches à lancer.
Exemple
2022-10-17 15:20:00,055|...|com.simplicite.util.CronJob|run||Execute job ObjectDynGC at 2022-10-17 15:20:00 from queue SysQueue
2022-10-17 15:20:00,057|...|com.simplicite.util.engine.CronManager|run||Event: Next cron job: deadlockTimestamp at Mon Oct 17 15:25:00 CEST 2022
2022-10-17 15:20:00,058|...|system|com.simplicite.util.engine.CronManager|run||Event: Next cron job: CheckClearCache at Mon Oct 17 15:25:00 CEST 2022
2022-10-17 15:20:00,059|...|com.simplicite.util.engine.CronManager|run||Event: Cron manager is sleeping for 0:04:59...
Si votre tache n’est pas là c’est que la cron n’a pas été correctement chargée / faire un reload ou clear cache / ou restart server.
Tous les triggers chargés sont tracés au démarrage, ensuite les logs n’indiquent que les prochaines à passer
INFO: 2022-10-17 15:36:29,549|..|com.simplicite.util.engine.CronManager|stop||Cron manager was stopped at Mon Oct 17 15:36:29 CEST 2022
2022-10-17 15:36:29,557|...|com.simplicite.util.engine.CronManager|loadTriggers||HealthCheck has been scheduled to run at: Mon Oct 17 16:00:00 CEST 2022 and repeat based on expression: 0 0 0/1 * * ?
2022-10-17 15:36:29,559|...|system|com.simplicite.util.engine.CronManager|loadTriggers||ModuleAutoUpdate has been scheduled to run at: Tue Oct 18 04:00:00 CEST 2022 and repeat based on expression: 0 0 4 * * ?
...
2022-10-17 15:36:29,560|...|com.simplicite.util.engine.CronManager|start||Cron manager was started at Mon Oct 17 15:36:29 CEST 2022
Merci de préciser ce que contiennent vos logs à ce niveau pour réduire le périmètre d’analyse.
J’ai fait un rechargement des logs hier soir. Effectivement, je n’avais pas vu qu’il affichait le planning dans les logs.
On constate bien que les 4 concernées sont aux abonnés absents.
Je vais recharger les CRON de ce pas et voir si la liste est complète pour cette nuit.
Ok tenez nous au courant mais si elle est affichée au chargement ça devrait être bon.
Depuis 10 ans personne ne nous a remonté de problème sur http://www.quartz-scheduler.org/
qui calcule le plan.
Par contre, si vous modifiez/créez une définition dans la cron à chaud, il faut obligatoirement recharger tout le plan via le bouton reload (ou via un ‘clear cache’ global ou restart tomcat plus violent).