Oui les exports ont fortement évolué notamment pour ne plus saturer la mémoire / pagination des recherches et flush sur disque ou directement dans la response HTTP suivant le média (export textuel CVS, ou binaire genre XLSX=ZIP forcement sur disque avant d’être envoyé).
Je ne vois pas en quoi cela ralentirait les exports (sauf les écritures disques plus longues qu’en mémoire).
Avez vous du code dans des hooks (pre-post search-select…) ?
Faites vous des tests 5.1/5.2 iso-du-reste ? même code/hook, même base/données ?
Par ailleurs pourquoi ne pas migrer/tester sur une 5.3 à jour ?
En 5.1 les gros exports finissent en heap/memory exception car écrivent en mémoire avant d’être retournés à l’appelant :
PrintWriter out = new PrintWriter(new StringWriter());
En 5.2+ l’API demande un PrintWriter, vous lui passez un fichier (quel chemin ?) donc la différence est le temps d’écriture sur disque, ou ce que fait la suite “saveFile”…
Via la UI, le back écrit directement dans le flux xhr/http pour avoir la progression.
Vous pouvez continuer à lui passer un StringWriter mais au risque de saturer le heap.
il faut préciser le chemin car par défaut, je ne sais pas où Tomcat va aller écrire ce fichier (à la racine de tomcat… ?). Pour écrire dans le répertoire tmp dans la webapp :
Platform.getTmpDir() + "/myfile.csv"
S’il y a 2 exports en parallèle, le nom du fichier est le même…
il faut donc un timestamp ou un random qq part, pour ça il y a des tools :
FileTool.getRandomFile(dir, prefix, extension)
Pensez à supprimer le fichier à la fin de votre traitement.
J’ai intégré les modifications que tu as remontées.
J’ai cependant un problème avec la méthode CSVTool.export et la suppression du fichier.
Sauf erreur de ma part, CSVTool.export lance une méthode asynchrone pour générer le fichier.
Comment puis-je vérifier que le traitement est bien terminé avant que la suppression du fichier ne se produise ?
De façon générale, je vais refaire le développement de cette fonctionnalité qui date de deux ans, et ne réponds plus au besoin actuel, tant sur la consommation mémoire que sur la vitesse d’exécution.
Le besoin initial est celui ci :
Pouvoir exporter une 30aines d’objet métier (la liste est figée), en format CSV (si possible en //) et les stocker dans un Field de type Document pour les laisser à disposition des gens, souhaitant télécharger le ZIP ainsi obtenu.
La nouvelle méthode CSVTool.export est synchrone, par contre elle pagine la recherche des objets et flush dans l’output stream au fur et à mesure des exports pour garder un espace mémoire limité.
Pour exporter en //, il faut veiller :
à exporter dans les fichiers disjoints (cf random file ou nommage qui dépende du login, date…)
à lancer des threads dans le pool de threads Simplicité pour en limiter le nombre en // (10 job asynchrones par défaut) : en lancer 30 en // ne sert à rien en soit car c’est le nombre de coeurs du serveur qui en le goulot d’étranglement
à utiliser un compteur global qui regarde si tout est terminé pour finaliser le traitement, par exemple :
int max = 30:
final AtomicInteger n = new AtomicInteger(max);
for (int i=0; i<max; i++)
JobQueue.push("my_export_" + i, new Runnable() {
@Override
public void run() {
// export object[i] in a isolated/unique file
CSVTool.export(...);
// all done ?
if (n.decrementAndGet()==0) {
// save a zip ...
}
}
});
Comment s’appellent les thread dont tu parles ?
Si tu en as plus, c’est que votre code instancie peut-être des threads et pas des runnable ?
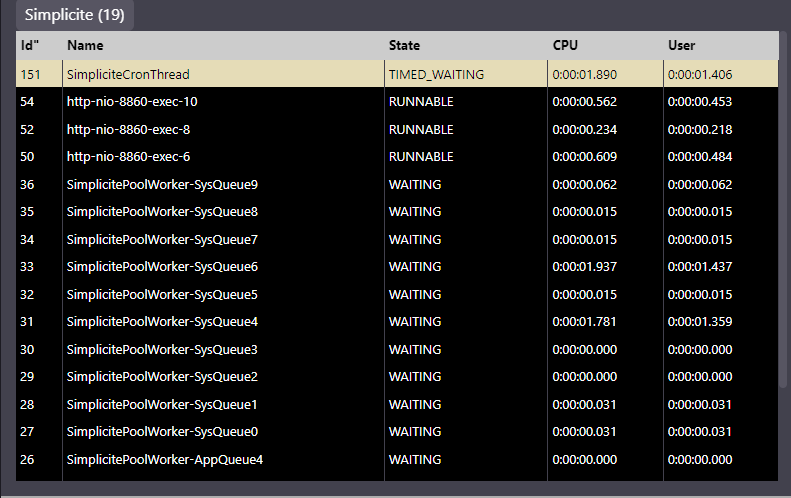
Par défaut, le pool est de 10 threads SimplicitePoolWorker qui attendent un job empilé dans le deamon SimpliciteCronThread. C’est largement suffisant car en général c’est le nombre de coeurs qui détermine la vraie limite physique.
Tu peux regarder la liste des threads Simplicité dans le monitoring en cliquant sur l’onglet “All threads” <=> “Simplicité”.
En V6, il y a 1 pool Système et 1 pool Applicatif pour ne pas bloquer les files d’attente système (GC, prune logs…) avec des applications qui consommeraient toute la bande passante.
Oui le pool est sensé être limité… un truc m’échappe.
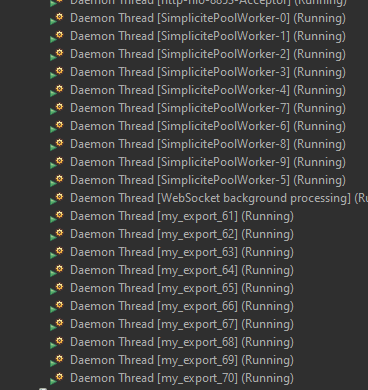
Avant Simplicité empilait des Threads qui prenaient beaucoup de ressources système (et souvent en nombre limité au niveau Tomcat) dans un état WAITING tant que pas de file disponible, donc on pouvait en empiler des millions et planter le serveur.
On a dû changer par des Runnable invisibles par Tomcat et qui sont lancés dans un thread alloué quand une des 10 files est disponible, donc quand on les voit c’est forcement en RUNNING (en empiler des millions finira par saturer le heap mais pas tomcat).
Si le CSVTool.export était asynchrone et rendait la main, tous les runnables termineraient rapidement.
Pour optimiser la consommation mémoire. Cependant où que je place l’instruction, je suis confronté par moment à une erreur ConcurrentModificationException.
J’ai pourtant mis un nom unique à chaque instance d’ObjectDB, et je fais le destroy après le :
Ok on a trouvé le problème en passant dans le JobQueue.push.
A mon avis c’est lié à un correctif suite à une remontée SonarQube.
Avant chaque worker faisait un run() du thread/runnable = appel bloquant, mais faire un run ce n’est pas exécuter le cycle de vie du Thread, c’est juste un appel à la méthode run, c’est mal.
Ca a été remplacé par un start() qui lance le thread proprement de manière asynchrone mais du coup ça redonne la main au worker qui continue de dépiler trop vite !
On va ajouter un join() pour bloquer le worker et attendre la fin de la tache avant de dépiler la suivante.
J’ai utilisé un Thread.sleep(30s) dans l’exemple à la place de l’export.
On voit bien que les taches sont dépilées 10 par 10.
Ce sera poussé dans une prochaine révision.
Ce ticket commence à être un fourre tout impossible à suivre.
Sans le code complet ni la stack complete, impossible de savoir à quel niveau ça bloque.
Il y a une concurrence d’accès quelque part.