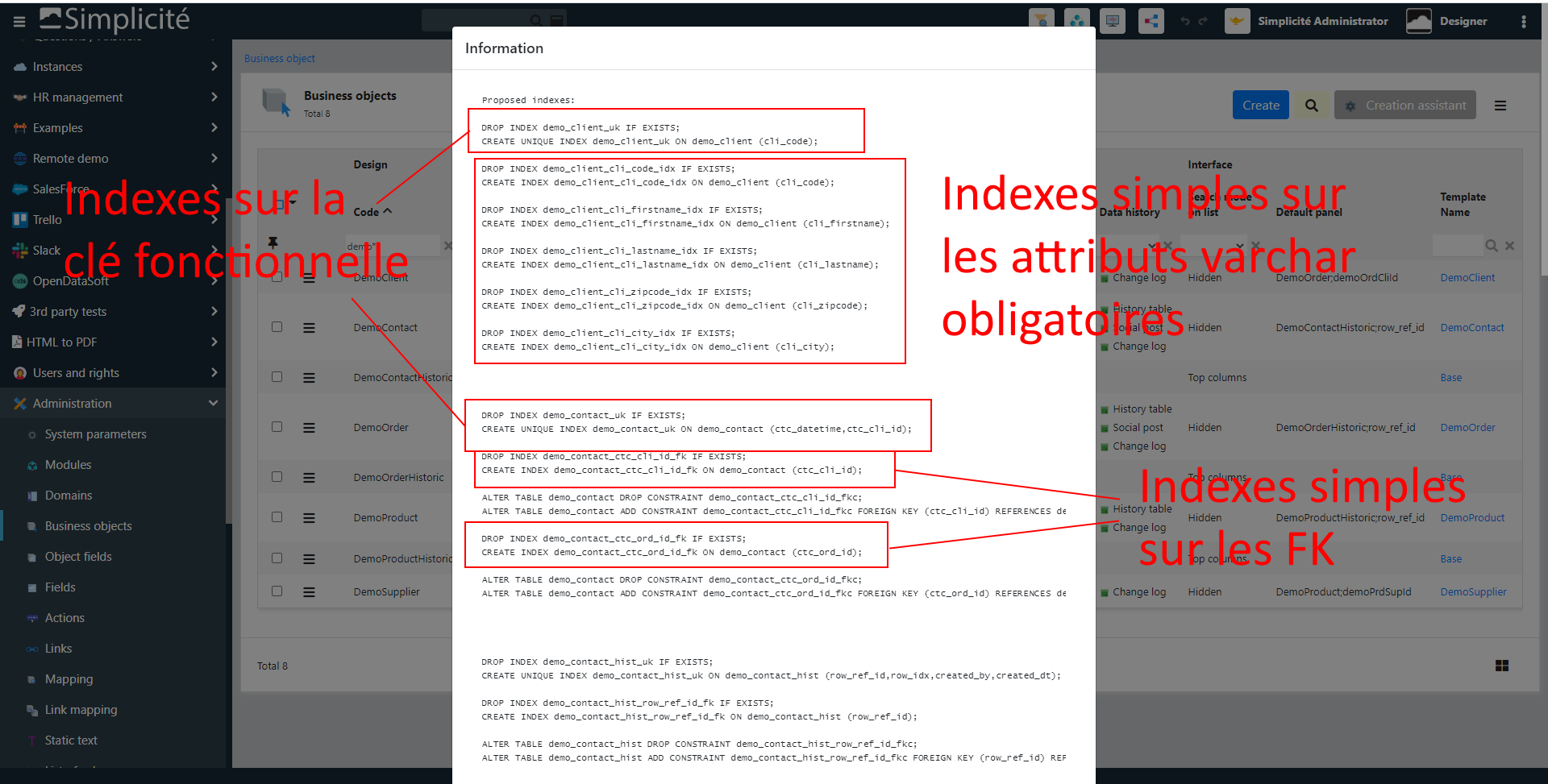
Quid des indexes de la table de cet objet (et des objets qui lui sont liés) ?
Pour mémoire, les indexes générés par défaut par Simplicité portent, outre la PK (= le row ID), sur les attributs de la clé fonctionnelle (index unique), sur les FK et sur les attributs de type string obligatoires (indexes simples):
Donc assurez vous déjà de bien regénérer ces indexes par défaut pour être sûr qu’ils sont à jour vis à vis du paramétrage.
Si besoin, ajoutez les indexes additionnels pertinents par rapport aux filtrages spécifiques que vous faites.
Mais de manière plus globale faites intervenir un DBA qui saura vous indiquer quels indexes ou autres sont les plus pertinents vis à vis vos cas d’usages et des requêtes SQL générées par Simplicité.
Rien de vraiment spécifique à Simplicité ici.
NB: avec certaines bases l’ordre des inner/outter joins peut avoir son importance, une manière de jouer sur cet ordre des jointures c’est en (ré)ordonnant vos attributs FK dans vos objets
Après régénération des index, le temps de traitement est en effet raccourci.
Nous avons cependant un problème lié aux utilisateurs ayant un périmètre important.
Ceux-ci ont alors un setSearchSpec contenant une clause IN de plus de 1 000 000 de row_id sur une table contenant (7 000 000 de lignes).
Y a-t-il un moyen d’optimiser le traitement du setSearchSpec en passant par une autre clause ou en changeant la façon de faire ? (Le setSearchSpec est défini dans le Hook postLoad).
Ce qu’il faut éviter de faire c’est un “IN” avec trop de valeurs fixes genre “in (1,12,24,72…)” qui serait calculé en Java en faisant une boucle suite à un search = car ça signifie aucune optimisation d’une requête coupée en 2 par code, et potentiellement une erreur SQL = request dont la longueur dépasse la taille max du driver JDBC (oracle est même limitatif sur le nombre d’arguments du in ORA-01795: maximum number of expressions in a list is 1000).
Que ce soit un “IN SELECT” ou un “EXISTS SELECT”, un simple EXPLAIN PLAN permettra voir si la jointure est indexée, les perfs sont équivalentes, mais s’il y a bcp de jointures l’ordre peut avoir un impact.