Un noeud dédié au batch me semble plus simple/pertinent qu’un datasource custom car ça impliquerait d’ajouter du code pour changer dynamiquement le datasource des objets utilisés dans le contexte d’un batch (un truc du genre if (contexte batch) then set datasource = datasource dédié aux batches dans le postLoad, si tant est que ça soit possible… je pense que c’est possible mais je n’ai jamais fait ça…).
Par contre je ne suis pas sûr de ce que peut signifier “déployer directement les batchs dans Kube” mais peut être que je ne comprends pas ce que signifie “batch” ici.
Pour moi un “batch” Simplicité c’est un traitement qui utilise des objets Simplicité (genre un import via un adapter) ça s’exécute donc sur une instance Simplicité.
Si votre “batch” n’utilise rien de Simplicité (ex: fait des insertions directes en base) ça peut potentiellement se lancer hors du contexte d’une instance Simplicité.
En 5.4 actuellement en dev (probablement la v6), les taches cron et les actions asynchrones pourront être associées à une File/Queue spécifique pour ne pas bloquer les autres threads (actions système).
On pourrait imaginer que chaque Queue utilise un pool d’accès différents pour laisser les autres disponibles aux accès API/UI
Mais à mon avis, avoir plusieurs pools/connecteurs JDBC sur la base déplacera le problème (accès en commited read global à toutes les connexions JDBC), il faut plutôt chercher à augmenter la taille du pool existant maxIdles ou utiliser des drivers JDBC plus performants (hikari, c3po…).
Si vous devez faire des traitements lourds sur les données (batch) en même temps que des accès API (TP transactionnels), vous avez un problème d’architecture applicative à analyser finement.
Il faut faire passer les batchs en dehors des heures d’ouverture du TP car allouer des ressources à l’un et à l’autre en parallèle finira toujours par un blocage du fait du “commited read” pour garantir l’intégrité des données du TP.
Bref monter une architecture batch performante, c’est arrêter le TP, alléger les contraintes en base le temps du traitement (geler les index, auto-commit…), augmenter certaines ressources (mémoire, timeout…). Et comme le dit @david si on doit faire de l’injection SQL pure autant utiliser les mécanismes de la base directement sans passer par du Java (SQL Loader, insert select, update en masse…).
Par contre, il faudra qu’à l’ouverture du TP, les tables Simplicité aient retrouvées “leurs petits” pour fonctionner : des indexes sur les UK/FK, des sequences bien calées, les timestamp des records… table historique ou redolog si besoin.
On a jamais utilisé ce mécanismes K8S mais je pense qu’on peut tout à fait envisager d’executer un container Simplicité temporairement pour processer un “batch” (au sens d’un batch Simplicité = l’execution d’un adapter).
Il faudra alors utiliser un entry point alternatif qui:
démarre l’instance (i.e. ce que fait l’entry point actuel, mais en background - ce que sait faire cet entrypoint)
attend que l’instance soit démarrée (ex: via des curls sur /ping)
appelle le traitement batch via curl sur le endpoint I/O
exit à la fin du traitement ci-dessus
Ou dans le genre.
Ca revient, fondamentalement, à dédier une instance aux traitements batchs (et les points de @Francois restent valables).
La solution de dédier une instance Simplicité aux batchs permettra de décharger la/les JVM qui servent aux sessions UI.
Si vos mises à jour en masse ne verrouillent rien de particulier en base (ou alors pas longtemps), ça devrait aller. Sinon il y aura un conflit entre les verrous des mises à jour UI vs batch en base.
Une analyse plus fine de vos traitements est nécessaire, mais ne pourra pas se faire via ce forum. Il y a surement des optimisations à trouver fonctionnellement avant de créer une infra surdimensionnée.
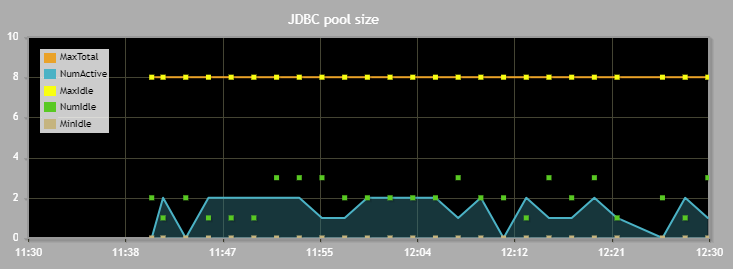
Pour info en 5.3, le besoin de monitoring du pool JDBC qui avait été exprimé il y a quelque temps déjà (je ne retrouve plus le post sur un forum privé probablement) a été réalisé.
Le chart sera accessible dans l’onglet Monitoring/Data.
Il donne des infos sur les connexions (actives et idles) à intervalle régulier :