Bonjour,
j’initie ce fil pour lister les bugs (ou problèmes) rencontrés dans le cadre de l’évaluation de la beta de la 5.3.0…
Bonjour,
j’initie ce fil pour lister les bugs (ou problèmes) rencontrés dans le cadre de l’évaluation de la beta de la 5.3.0…
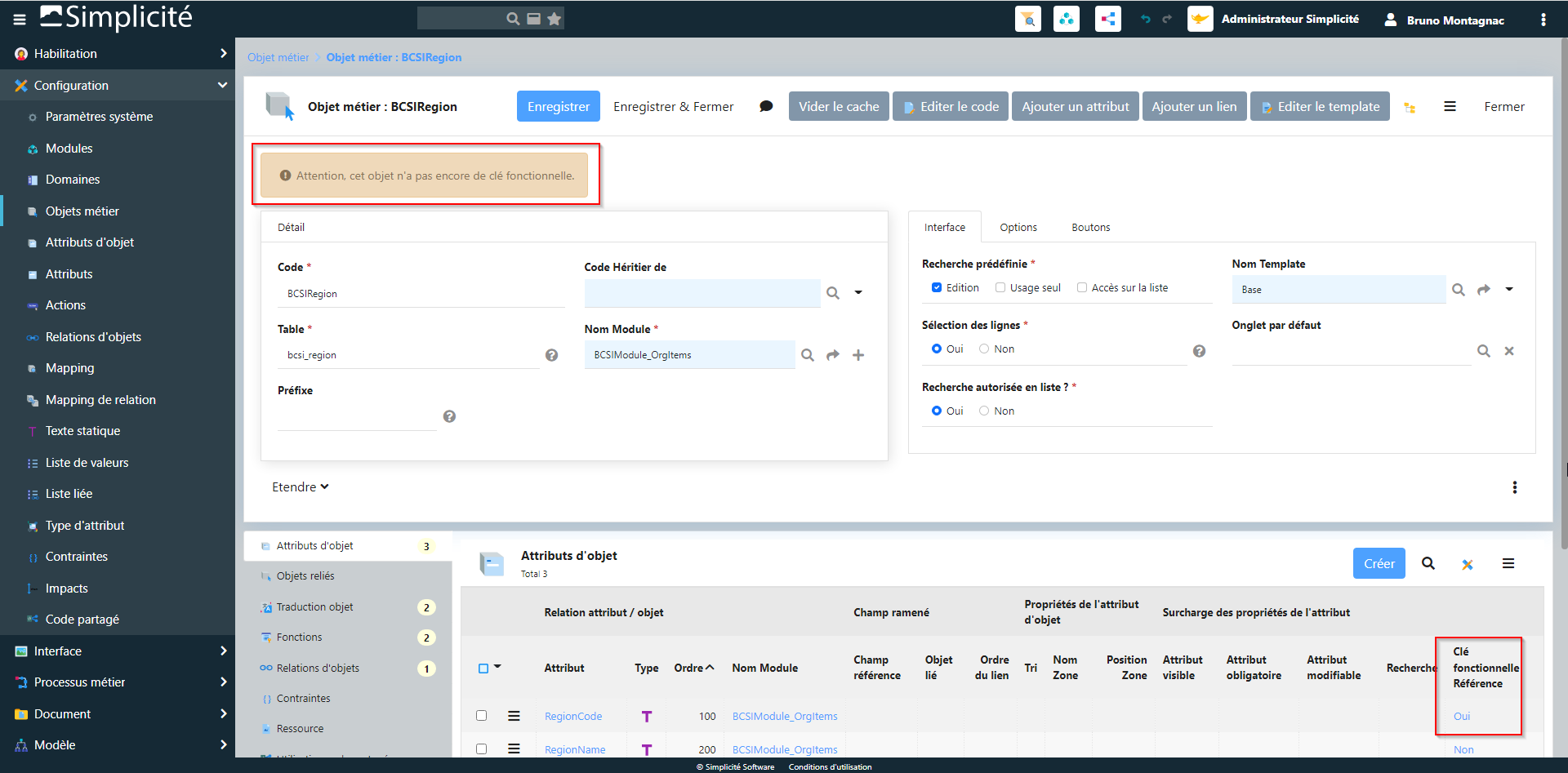
Petit problème de prise en compte de la propriété clé fonctionnelle définie au niveau de l’attribut et pas reprise au niveau de l’attribut d’objet…
Je me répond à moi-même : après un clear cache l’alerte disparaît et l’ObjectField est bien considéré comme “clé fonctionnelle” de l’objet.
Si je comprends bien le dispositif de synchronisation master/slave, la seule fonction qui permet de diffuser depuis un master vers un slave est la fonction synchronize. Cette fonction doir être instanciée sur le slave qui va pull les données disponibles sur le master à partir d’une date de référence dite “date de dernière mise à jour” (ou date de dernière synchro).
Soit je n’ai pas compris comment ça doit fonctionner soit il y a un loup…
Bonsoir, avez-vous une documentation plus détaillée de la mise en oeuvre des DataLinks que ce qui est dans la release notes 5.3 ?
Ce mécanisme est très (très) intéressant et nous bâtissons d’ores et déjà des plans sur son usage.
Effectivement les supports ne sont pas à jour. On va l’inclure.
En attendant et en résumé :
Au runtime :
_SYNC_MASTER_<object> pour ne pas refaire un full-scan. Tous les objets ayant été modifiés depuis cette date sont resynchronisés. Supprimer ces paramètres = full synchroLimitation actuelle :
m_object_usage reste pour une concurrence d’accès local pour le moment).Une doc a été ajoutée en dessous de celle des remote objects.
https://docs.simplicite.io/documentation/05-remote/simplicite.md
Il manque encore le support de formation / docs2 et quelques copies d’écran, mais rien de bien compliqué quand on a compris les grands principes.
Ce serait également un bon exemple d’ajouter également au Simpli-store un exemple de datalink sur la démo qui serait abonnée aux “fournisseurs + produits” mis à jour dans une application de gestion des stocks.
Merci beaucoup François pour ces éléments.
Je ne comprends toujours pas où ça coince…
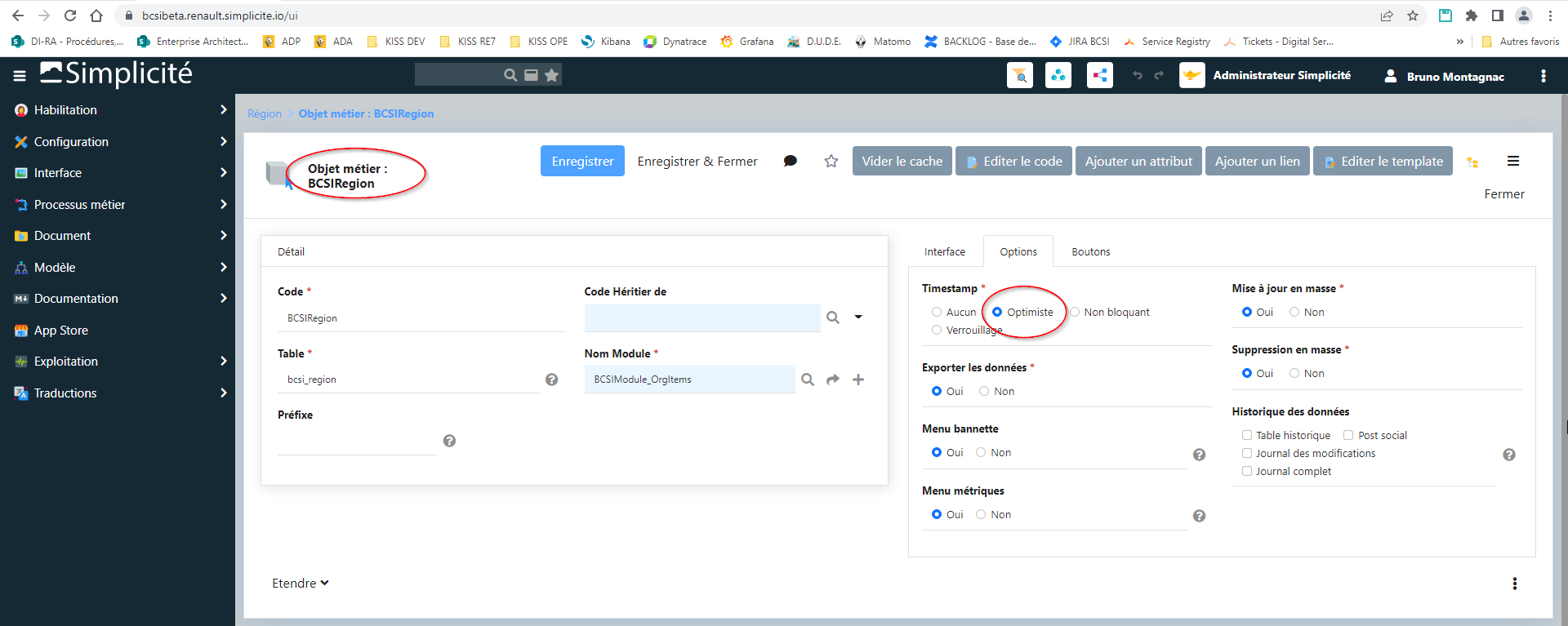
L’objet métier (BCSIRegion) est bien configuré dans un même module chargé sur le master (bcsibeta) et le slave (bcsimsea) avec “timestamp” activée (en l’occurrence, l’option “optimiste”)
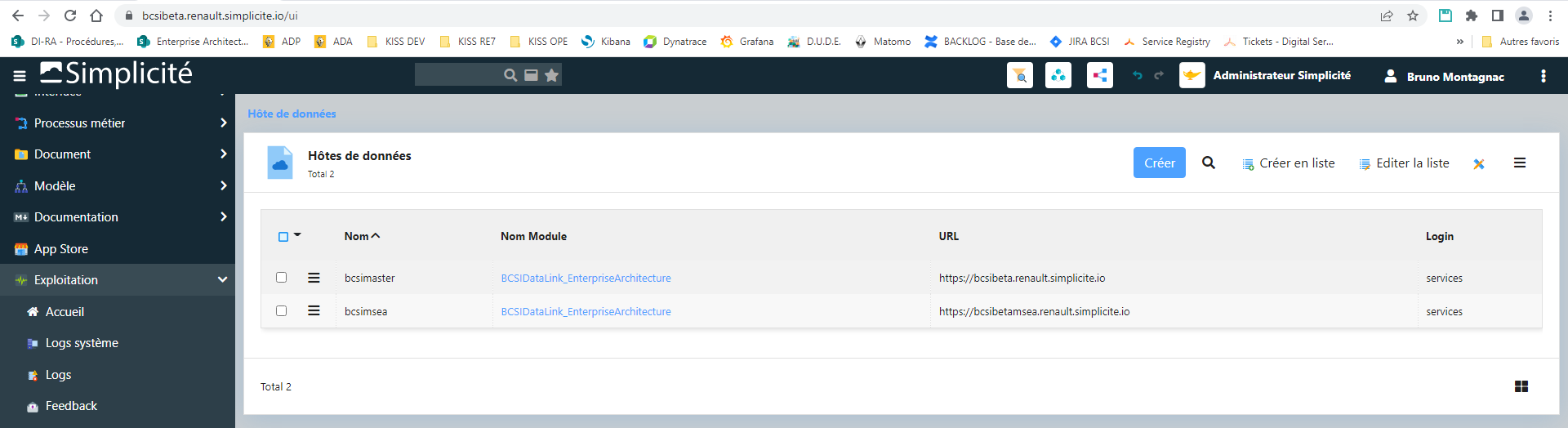
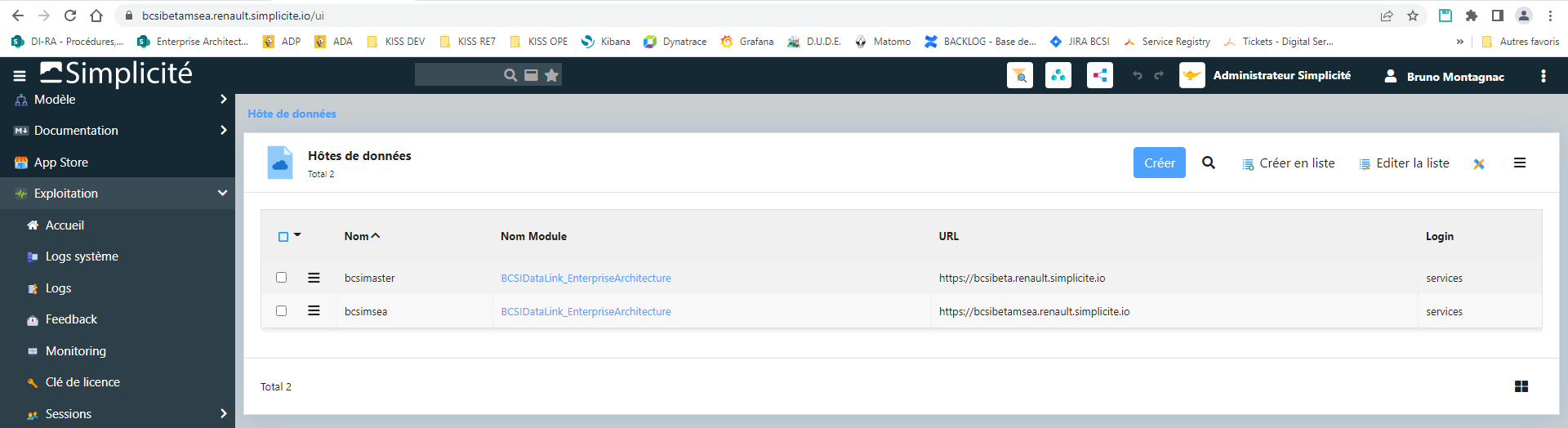
J’ai bien défini les hosts côté master (bcsibeta) et slave (bcsimsea) :
Les DataLinks sont définis de manière identique sur le master et le slave tels que :
Lorsque je procède à une full synchro (sur le slave) avec une date antérieure à l’initialisation dans le master, tout est synchronisé dans le slave → ici je comprends que c’est bien le comportement attendu.
Mais lorsque je réactive la tâche cron (sur le slave) qui s’appuie sur la date de dernière synchro (cf. étape précédente), toutes les lignes ayant un timestamp antérieur à la dernière synchro sont supprimées et seules les lignes modifiées (dans le master) postérieurement à la synchro sont conservées et mises à jour (dans le slave) → là je pense que ce n’est pas ce qui est attendu ou alors je n’ai pas compris le concept…
Bizarre effectivement, le cas de la suppression me laisse perplexe… on doit avoir traité ça pas un annule et remplace qui en fait un peu trop…
on regarde.
L’algo de synchro en masse se passe en 2 temps :
Le filtre sur la date est surement inopérant, et ça supprime trop loin dans le passé. On va renforcer le filtre qui pourtant est une search-spec sur le champ updated_by.
Ok merci!
Par contre je ne saisi pas pourquoi le updated_by est pris en compte lors de la synchronisation… quel est le usecase ? Seuls les records modifiés par un user en particulier seraient synchronisés ?
Autre question : quels sont les triggers de resynchro autres que le cron ou le clear cache ?
erreur de ma part, on parle bien de “update_dt” uniquement.
on va renforcer la boucle qui cherche les lignes à détruire, le filtre peut effectivement sauter lors de la pagination (hooks, resetFilters…).
les resynchro en masse sont par cron en utilisant la date de dernier scan
ou via l’action sur le datalink qui permet de forcer la date de début de scan via UI
sinon la synchro unitaire se fait lors de chaque save/delete.
Bug reproduit, même en renforçant les filtres pour ne pas supprimer les records suite à une resynchro depuis une certaine date. La tache cron fait un peu trop le ménage.
On va analyser ça de plus près.
UPDATE : tache cron DataLink
Problème d’arrondi corrigé: le scan (qui démarre à T1) cherchait à tord de la date de dernier passage T0, alors qu’on doit chercher à T0+1 seconde, et à la fin si pas d’erreur on dit que T1 devient la date de dernier passage T0. Les records qui se trouvaient sur la ligne T0 après 1 premier full-scan se faisait massacrer, ça ne se produira plus :
Merci pour les fix… Je teste un nouveau cas:
Est-ce le comportement attendu / une limite du dispositif ?
Mon besoin serait que si le slave est en capacité de s’aligner sur le master (i.e. aucune règle du modèle métier n’interdit la suppression du record dans le modèle du slave) la suppression soit opérée. Sinon (suppression interdite) on laisse le record en place sur le slave avec idéalement un event “DESYNCHRO” tracé sur le record en question (cf. log EVENT/level ERROR dans les opérations du slave).
Bonjour Bruno,
Ca ne doit pas fonctionner dans le vieux mode de suppression qui ne passe pas par les hooks
(si DELETE_CHILD_HOOK=no). On ne l’utilise plus car ça n’applique pas les règles de delete cascade.
Dans la version qui arrive :
A restester quand on aura rebuildé les images 5.3 car ça corrige peut-être ton cas.
En cas d’erreur de suppresssion côté slave il y aura une trace :
AppLog.error("syncData: delete error " + err + " on object " + uk, null, null);
Et côté Master, il y aura aussi des traces qui signalent les appels “sync” vers un slave.
Si la suppression est toujours KO, il faudra voir plus en détail pourquoi au niveau des droits ou du paramétrage (filtre sql, hook ?). Si c’est côté master ou salve…
ok en fait j’ai l’impression qu’aucune mise à jour synchrone entre le master et le slave… je dois avoir un loup dans la conf…
Partage ton paramétrage de DataLink
https://docs.simplicite.io/documentation/05-remote/simplicite.md
Attention la 5.3.0-beta n’a pas été rebuildée depuis le 23/09, un build est prévu ce soir
<?xml version="1.0" encoding="UTF-8"?>
<simplicite xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.simplicite.fr/base" xsi:schemaLocation="http://www.simplicite.fr/base https://www.simplicite.io/resources/schemas/base.xsd">
<object>
<name>DataLinkHost</name>
<action>upsert</action>
<data>
<dlh_name>bcsimaster</dlh_name>
<row_module_id.mdl_name>BCSIDataLink_EnterpriseArchitecture</row_module_id.mdl_name>
<dlh_url>https://bcsibeta.renault.simplicite.io</dlh_url>
<dlh_user>services</dlh_user>
<dlh_pwd>xxx</dlh_pwd>
</data>
</object>
<object>
<name>DataLinkHost</name>
<action>upsert</action>
<data>
<dlh_name>bcsimsea</dlh_name>
<row_module_id.mdl_name>BCSIDataLink_EnterpriseArchitecture</row_module_id.mdl_name>
<dlh_url>https://bcsibetamsea.renault.simplicite.io</dlh_url>
<dlh_user>services</dlh_user>
<dlh_pwd>xxx</dlh_pwd>
</data>
</object>
<object>
<name>DataLinkHosts</name>
<action>upsert</action>
<data>
<dlk_link_id.dlk_name>Interface microservice EA - MDM</dlk_link_id.dlk_name>
<dlk_host_id.dlh_name>bcsimaster</dlk_host_id.dlh_name>
<dlk_type>M</dlk_type>
<row_module_id.mdl_name>BCSIDataLink_EnterpriseArchitecture</row_module_id.mdl_name>
</data>
</object>
<object>
<name>DataLinkHosts</name>
<action>upsert</action>
<data>
<dlk_link_id.dlk_name>Interface microservice EA - MDM</dlk_link_id.dlk_name>
<dlk_host_id.dlh_name>bcsimsea</dlk_host_id.dlh_name>
<dlk_type>S</dlk_type>
<row_module_id.mdl_name>BCSIDataLink_EnterpriseArchitecture</row_module_id.mdl_name>
</data>
</object>
</simplicite>
Je pense que c’est là que le bât blesse…