Request description
Bonjour,
Suite à la présentation du 6 novembre, nous avons pu mieux expérimenter la création d’un processus métier standard et cela nous a donné plusieurs idées d’implémentation métier ( Merci encore pour l’enregistrement , super utile ! ).
Nous souhaiterions aussi mieux comprendre certaines fonctionnalités natives liées à l’analyse de processus, je n’ai pas pu trouver de docs ou exemple dans la démo avec l’utilisation de ses fonctionnalités.
Existe-t-il une documentation détaillée ou un exemple de configuration complet sur ces modules (graphiques, indicateurs, dossier processus/activité, suivi des activités,alerte…) ?
Besoin métier / use case
Je souhaite savoir si les fonctionnalités standards de suivi des processus peuvent m’aider dans un scénario de ce type.
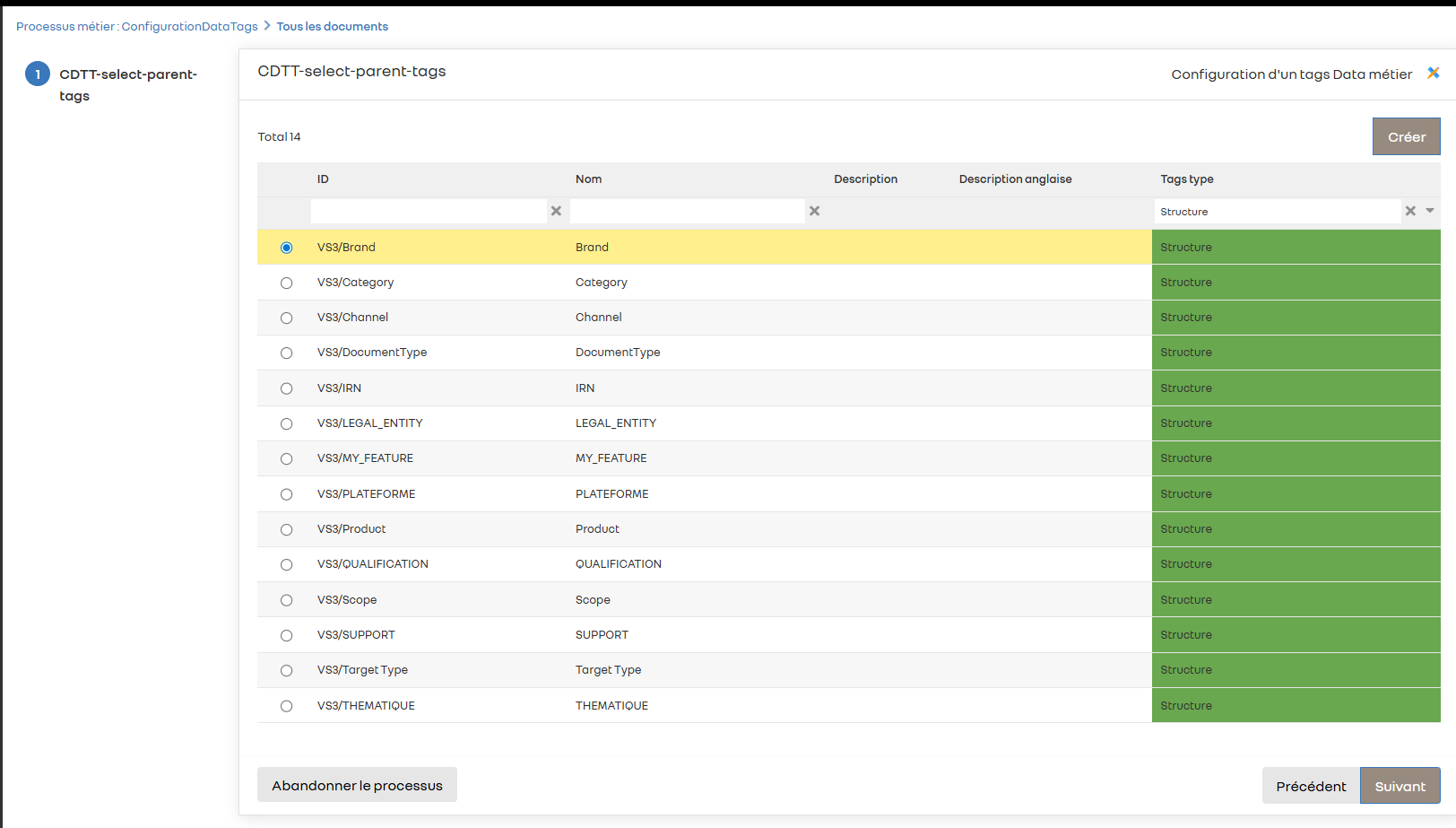
Contexte rapide : nous avons un objet Tags, avec la possibilité d’avoir un tagsParent (relation parent → enfant), ainsi que des tagsLocale par locale possible (fr-FR, en-GB, …), donc une relation 1-N entre Tags et TagsLocale.
et voici pour le moment le processus que l’on a imaginé :
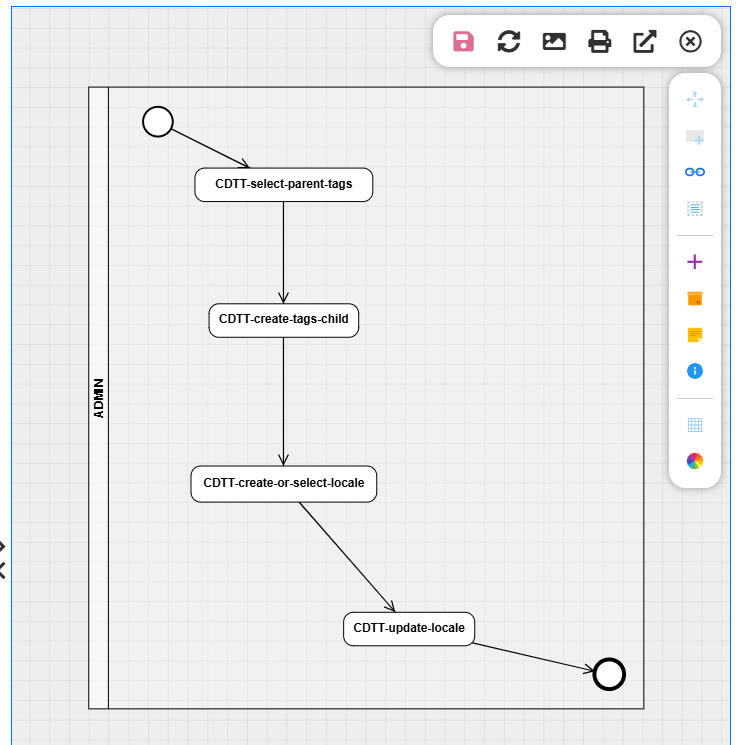
L’objectif serait le suivant :
-
Un utilisateur A démarre un processus
→ Celui-ci selectionne de la data pour crée un objet métier A. ( dans notre exemple selection d’un tagsParent et la creation d’un tags enfant.) -
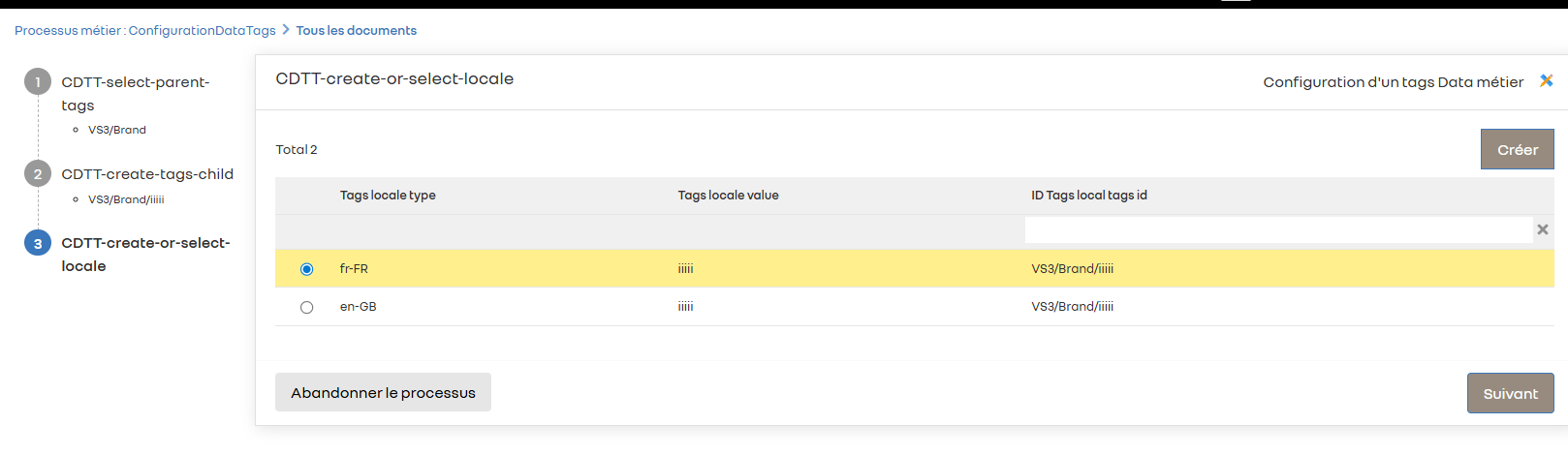
L’utilisateur A peut continuer pour renseigner les locales ou finir le process mais le processus devra rester ouvert le temps qu’un autre utilisateur B complète certaines données si nécessaire. ( dans notre exemple les traductions locale de tags)
-
Un utilisateur B reprend et termine le processus, en ajoutant les données complémentaires, jusqu’à la complétion totale du parcours.( toute les locales associé au tags)
Résumé, & Questions que l’on se pose :
Idéalement, nous aimerions utiliser les écrans natifs (dossier processus, dossier activité, tableau de bord) pour :
- suivre l’avancement des différents processus,
- identifier les tâches en attente,
- filtrer par utilisateur / rôle,
- analyser la charge / temps de traitement,
- obtenir une vue consolidée de tous les processus actifs.
Les écrans “Dossier processus”, “Dossier activité” et le tableau de bord peuvent-ils servir de base à un tel suivi ? Sont-ils configurables et dans quelle mesure ?
Le tableau de bord présent dans la démo semble prendre en compte certains objets (ex. Demande / Order).
-
Comment fonctionne la sélection des objets utilisés dans ces graphiques ? (est-ce lié à l’activation des tables d’historique ?)
-
Peut-on ajouter ou intégrer nos propres objets métiers dans ces statistiques standard ?
J’émets toutes ces hypothèses en voyant le nom de certains attributs liés à ces objets, mais sans certitude. ![]()
Nous sommes ouverts à toute proposition ; l’idée n’est pas figée. Si le use case nécessite plusieurs processus métiers, aucun problème.
Technical information
Instance /health
--- [Platform]
Status=OK
Version=6.2.18
BuiltOn=2025-10-31 21:07
Git=6.2/2cc6bf5900a7ae1bba8c53a06751e86976b99eaf
Encoding=UTF-8
EndpointIP=100.88.218.203
EndpointURL=http://lbc-77449-app-58c587c94c-r2b87:8080
TimeZone=Europe/Paris
SystemDate=2025-12-03 10:28:28
[Application]
ApplicationVersion=1.0.0
ContextPath=
ContextURL=https://ldm-app.ext.gke2.dev.gcp.renault.com
ActiveSessions=1
LastLoginDate=2025-12-03 09:43:53
[Server]
ServerActiveSessions=1
ServerSessionTimeout=30
CronStarted=true
[JavaVM]
HeapFree=194045
HeapSize=378880
HeapMaxSize=3045376
TotalFreeSize=2860541
[Cache]
ObjectCache=541
ObjectCacheMax=10000
ObjectCacheRatio=5
ProcessCache=1
ProcessCacheMax=10000
ProcessCacheRatio=0
APIGrantCache=0
APIGrantCacheMax=1000
APIGrantRatio=0
[Healthcheck]
Date=2025-12-03 10:28:28
ElapsedTime=7 ---
Simplicité logs
---paste the content of the **relevant** server-side logs---
Browser logs
---paste content of the **relevant** browser-side logs---
Other relevant information
----E.g. type of deployment, browser vendor and version, etc.----