nous rencontrons un blocage lié à la recherche fulltext sur des champs indexés et l’utilisation de IndexCore.searchIndex().
Nous observons une différence entre les résultats de recherche utilisant cette méthode et celle de la vue ObjectIndex présente dans le menu Operation.
Steps to reproduce
This request concerns an up-to-date Simplicité instance
and these are the steps to reproduce it:
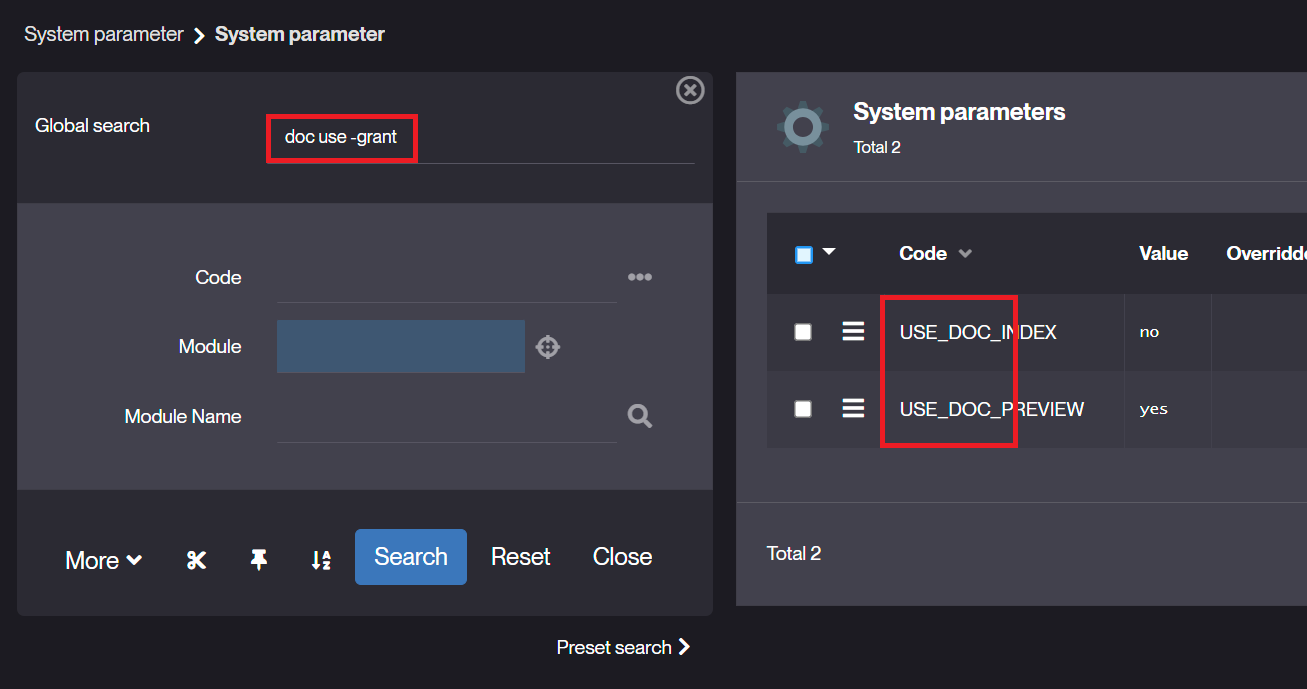
Objet Metier: option ‘indexable’ = oui et champs de type texte long option ‘indexable’ = oui.
2.Remplir le champs cible avec un texte comportant un caractère spécial.exemple : &
Recherche dans ObjectIndex dans menu Opération (Like )
Recherche en utilisant la méthode IndexCore.searchIndex() (Match Against)
Une traduction/remplacement des charactères spéciaux si ils se trouvent à l’intérieur de guillemets (afin de pas pertuber les opérateurs en BOOLEAN MODE) à la soumission d’un record de l’objet ( lors du preSave()) et pour la recherche lors du preSearchIndex().
Exemple : le signe & devient ampersand_sign.
Resultats :
Etape 3 :
Demande
De part sa nature unitaire lié à l’objet, ce contournement devient une dette à gérer sur une multitude d’objet métiers du modèle.
Serait-il possible d’uniformiser ce contournement au niveau du socle Simplicité afin de profiter de cette abstraction de manière globale sans toucher au modèle ?
Effectivement la recherche PGSQL via le parser to_tsquery est formelle/complexe et le parser actuel est un peu trop basique pour convertir une recherche utilisateur en syntaxe PG formelle. De plus à ma connaissance, il n’y pas de syntaxe d’échappement pour les caractères spéciaux (&:*|() … ), bref que du bonheur
@bmo Bruno avait ouvert un sujet à propos du plus/minus suite à son analyse très documentée :
Nous avons un sujet de R&D dans notre backlog à ce propos, et n’avons pas pris le temps d’étudier l’usage de websearch_to_tsquery qui semble la bonne approche, mais qui ne va pas ajouter de suffixe :* à chaque terme comme actuellement (commence par).
Suite à analyse sur PGSQL, une requête de recherche plus optimale serait de :
utiliser websearch_to_tsquery qui évite les pb de to_tsquery (pb de caractères spéciaux, de +/-, etc. et surtout d’erreur de parsing de la requête utilisateur par Simplicité )
de concaténer les 2 colonnes (clé fonctionnelle idx_ukey et fulltext idx_all) à la place d’un “or entre deux @@”
utiliser une langue autre que “simple” qui visiblement est la cause des recherches tronquées
utiliser ts_rank comme scoring pour le tri
ajouter un index sur les 2 colonnes préparées en vecteur
exemple :
CREATE INDEX m_index_ft ON m_index
USING GIN (to_tsvector('english', idx_ukey || ' ' || idx_all));
SELECT *, ts_rank(
to_tsvector('english', idx_ukey || ' ' || idx_all),
websearch_to_tsquery('english', 'my front-end query')) rank
FROM m_index
WHERE to_tsvector('english', idx_ukey || ' ' || idx_all)
@@ websearch_to_tsquery('english', 'my front-end query')
ORDER BY rank desc, idx_ukey asc
Avec l’index, on passe à 70ms au lieu de 400ms sur des recherches simples.
On va préparer ça pour la 6.1. On verra pour backporter en 5.3 si vous ne prévoyez pas d’upgrade d’ici peu.
Se pose le pb de la langue à utiliser… french or english. Je propose une variable ou la langue du user public ? @bmo@JordanSO
Je ne sais pas trop quelles sont les implications du choix de la langue.
Il y a toujours la langue choisie par l’utilisateur dans le contexte : celle de sa session UI Simplicité ou celle choisie dans notre portail (Anglais/Français) et prise en compte dans l’ouverture de la session API. Quel que soit le canal utilisé, ce sera restitué par getGrant().getLang().
m_index stocke les données saisies qui n’est pas forcement la langue de l’utilisateur qui sert à afficher le contenant, mais pas le contenu lui-même.
On ne sait pas si les données sont saisies en Français ou en Anglais ou en Allemand…
Mais l’index PG est par langue pour optimiser les phonèmes / mots inutiles.
Ok… alors pour le coup, la situation est la suivante :
Du point de vue métier, il y a ceux qui ne veulent pas s’en préoccuper et ceux qui insistent pour garantir la disponibilité et l’accessibilité de leur documentation dans plusieurs langues… le grand écart quoi.
dans la plupart des cas, un objet aura des propriétés textuelles documentées dans une langue non déterminée (on a du français, de l’anglais, du Coréen, …)
dans certains cas, on aura modélisé des champs textuels dédiés à une langue (ex. descriptionFR, desccriptionEN) qui seront tout les deux indexés mais pas toujours documentés.
dans la plupart des cas c’est de l’anglais qui est saisi mais pas toujours dans le champ prévu (le cas échéant).
On a les utilisateurs qu’on mérite…
Du mon côté, je rêve d’un seul champ textuel dans le modèle renseigné dans la langue choisie par l’utilisateur qui documente et traduit à la volée lors de la présentation (par exemple via un petit call à l’API IA deep’L) dans la langue choisie par l’utilisateur qui consulte.
Je ne sais pas trop comment l’index peut s’intercaler dans tout ça… et puis ce n’est qu’une vision pas encore stabilisée.
Oui on va savoir faire nativement (ça fonctionne déjà sans être complètement intégré), c’est un autre sujet de R&D côté IA pour traduire à la volée du texte. Dans l’idée, on aura une langue unique en base (disons ENU) :
read = traduction en front dans la langue du user (ex ENU>FRA + éventuellement un bouton “voir la langue source”)
save = traduction dans la langue en base (FRA>ENU)
le champ de type “text long” devra avoir une propriété pour lui lier la config d’un traducteur (deepL ou autre) au runtime
par contre pas de garantie que la re-traduction au save d’un texte traduit à l’affichage soit l’identité (ex bidon: Good morning > Bonjour > Hello)
Une autre approche serait d’avoir autant de colonnes que de langues et de pré-traduire toutes les langues, mais ça ne résoud pas le pb de re-traduction entre langues.
Une autre serait de stocker en base dans langue du user avec un prefix “FRA:bonjour” qui serait traduit et modifié en “ENU:hello” par un English US, et ainsi de suite.
Bref en attendant, on va gérer dans un premier temps un paramètre PGSQL_TSLANG qui vaudra english par défaut si absent. Ca semble bien fonctionner même pour une texte en Français, mais ça prend un peu plus de place car les “le la les” ne seront pas ignorés.
On va livrer cette évolution dans la prochaine 6.1 et vous nous ferez des retours sur vos cas d’usage.
Bonjour,
je me permet de vous interpeller sur ce topic car ça concerne IndexCore.searchIndex() même si le sujet est différent.
j’ai remarqué que la requete SQL (MySQL) produite par la méthode avec une phrase exacte, c’est-à-dire entre guillemet ne respecte pas la syntaxe MySql à cause de la combinaison : " phrase " + *
Example de query:
Bribe de texte recherché: “vehicle parts”
Query de la méthode searchIndex() : SELECT idx_key, idx_object, idx_row_id, idx_ukey, idx_all, MATCH (idx_ukey, idx_all) AGAINST ('"vehicle parts" *' IN BOOLEAN MODE) AS score FROM m_index WHERE MATCH (idx_ukey, idx_all) AGAINST ('"vehicle parts" *' IN BOOLEAN MODE) AND idx_object in ('ObjetMetier') ORDER BY score desc, idx_ukey
ce qui cause l’erreur : Error: syntax error, unexpected $end, expecting FTS_TERM or FTS_NUMB or '*'
Est-il possible actuellement de faire en sorte que * ne soit pas rajouté par défaut dans la requête (avec un paramètre ?) ou c’est “en dur” ?
Effectivement si la recherche BOOLEAN MODE ne contient pas de AND ou OR, Simplicité lui ajoute une wildcard * (commence par) pour simplifier la vie de l’utilisateur. Mais il faudrait ne pas en ajouter si c’est une phrase exacte entre quotes, on va la retirer dans ce cas.
Cette requête fonctionne bien sur une base MySQL 8.0 avec ou sans wildcard.
Quelle est votre version ?
Nous ne testons plus cette version de MySQL 5.
La wildcard a été retirée si la recherche est une phase entre quotes.
Avez vous pu tester si cela corrige votre cas avec une version à jour ?